 README
¶
README
¶
Ratchet

A library for performing data pipeline / ETL tasks in Go.
The Go programming language's simplicity, execution speed, and concurrency support make it a great choice for building data pipeline systems that can perform custom ETL (Extract, Transform, Load) tasks. Ratchet is a library that is written 100% in Go, and let's you easily build custom data pipelines by writing your own Go code.
Ratchet provides a set of built-in, useful data processors, while also providing an interface to implement your own. Conceptually, data processors are organized into stages, and those stages are run within a pipeline. It looks something like:
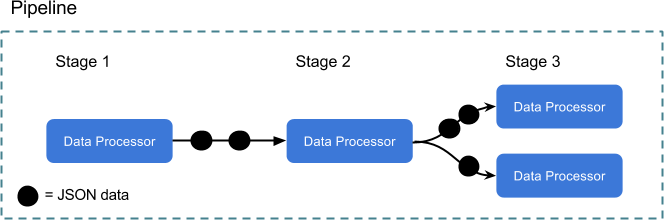
Each data processor is receiving, processing, and then sending data to the next stage in the pipeline. All data processors are running in their own goroutine, so all processing is happening concurrently. Go channels are connecting each stage of processing, so the syntax for sending data will be intuitive for anyone familiar with Go. All data being sent and received is JSON, which provides for a nice balance of flexibility and consistency.
Getting Started
-
Check out the full Godoc reference:

-
Get Ratchet: go get github.com/dailyburn/ratchet
Ratchet comes with vendored dependencies so it can work out of the box if you use go1.6 (or go1.5 with the GO15VENDOREXPERIMENT environment variable set to 1).
However, if you prefer to vendor your own dependencies then you should move the dependencies out of ratchet's vendor/ folder and into your own. Read the vendor/vendor.json file to get a list of its dependencies and their versions. Ratchet works with the vendor-spec, so it will also work with the govendor dependency manager. After you have copied the dependencies into your project's vendor.json, you can download them into your project's vendor folder--along with ratchet--by running:
govendor sync govendor add github.com/dailyburn/ratchet govendor add github.com/dailyburn/ratchet/data govendor add github.com/dailyburn/ratchet/logger govendor add github.com/dailyburn/ratchet/processors govendor add github.com/dailyburn/ratchet/util
While not necessary, it may be helpful to understand some of the pipeline concepts used within Ratchet's internals: https://blog.golang.org/pipelines
Why would I use this?
Ratchet could be used anytime you need to perform some type of custom ETL. At DailyBurn we use Ratchet mainly to handle extracting data from our application databases, transforming it into reporting-oriented formats, and then loading it into our dedicated reporting databases.
Another good use-case is when you have data stored in disparate locations that can't be easily tied together. For example, if you have some CSV data stored on S3, some related data in a SQL database, and want to combine them into a final CSV or SQL output.
In general, Ratchet tends to solve the type of data-related tasks that you end up writing a bunch of custom and difficult to maintain scripts to accomplish.
 Documentation
¶
Documentation
¶
Overview ¶
Package ratchet is a library for performing data pipeline / ETL tasks in Go.
The main construct in Ratchet is Pipeline. A Pipeline has a series of PipelineStages, which will each perform some type of data processing, and then send new data on to the next stage. Each PipelineStage consists of one or more DataProcessors, which are responsible for receiving, processing, and then sending data on to the next stage of processing. DataProcessors each run in their own goroutine, and therefore all data processing can be executing concurrently.
Here is a conceptual drawing of a fairly simple Pipeline:
+--Pipeline------------------------------------------------------------------------------------------+ | PipelineStage 3 | | +---------------------------+ | | PipelineStage 1 PipelineStage 2 +-JSON---> | CSVWriter | | | +------------------+ +-----------------------+ | +---------------------------+ | | | SQLReader +-JSON----> | Custom DataProcessor +--+ | | +------------------+ +-----------------------+ | +---------------------------+ | | +-JSON---> | SQLWriter | | | +---------------------------+ | +----------------------------------------------------------------------------------------------------+
In this example, we have a Pipeline consisting of 3 PipelineStages. The first stage has a DataProcessor that runs queries on a SQL database, the second is doing custom transformation work on that data, and the third stage branches into 2 DataProcessors, one writing the resulting data to a CSV file, and the other inserting into another SQL database.
In the example above, Stage 1 and Stage 3 are using built-in DataProcessors (see the "processors" package/subdirectory). However, Stage 2 is using a custom implementation of DataProcessor. By using a combination of built-in processors, and supporting the writing of any Go code to process data, Ratchet makes it possible to write very custom and fast data pipeline systems. See the DataProcessor documentation to learn more.
Since each DataProcessor is running in it's own goroutine, SQLReader can continue pulling and sending data while each subsequent stage is also processing data. Optimally-designed pipelines have processors that can each run in an isolated fashion, processing data without having to worry about what's coming next down the pipeline.
All data payloads sent between DataProcessors are of type data.JSON ([]byte). This provides a good balance of consistency and flexibility. See the "data" package for details and helper functions for dealing with data.JSON. Another good read for handling JSON data in Go is http://blog.golang.org/json-and-go.
Note that many of the concepts in Ratchet were taken from the Golang blog's post on pipelines (http://blog.golang.org/pipelines). While the details discussed in that blog post are largely abstracted away by Ratchet, it is still an interesting read and will help explain the general concepts being applied.
Creating and Running a Basic Pipeline ¶
There are two ways to construct and run a Pipeline. The first is a basic, non-branching Pipeline. For example:
+------------+ +-------------------+ +---------------+ | SQLReader +---> CustomTransformer +---> SQLWriter | +------------+ +-------------------+ +---------------+
This is a 3-stage Pipeline that queries some SQL data in stage 1, does some custom data transformation in stage 2, and then writes the resulting data to a SQL table in stage 3. The code to create and run this basic Pipeline would look something like:
// First initalize the DataProcessors read := processors.NewSQLReader(db1, "SELECT * FROM source_table") transform := NewCustomTransformer() // (This would your own custom DataProcessor implementation) write := processors.NewSQLWriter(db2, "destination_table") // Then create a new Pipeline using them pipeline := ratchet.NewPipeline(read, transform, write) // Finally, run the Pipeline and wait for either an error or nil to be returned err := <-pipeline.Run()
Creating and Running a Branching Pipeline ¶
The second way to construct a Pipeline is using a PipelineLayout. This method allows for more complex Pipeline configurations that support branching between stages that are running multiple DataProcessors. Here is a (fairly complex) example:
+----------------------+
+------> SQLReader (Dynamic) +--+
| +----------------------+ |
| |
+---------------------------+ | +----------------------+ | +-----------+
+-----> SQLReader (Dynamic Query) +------+ +--> Custom DataProcessor +-------> CSVWriter |
+-----------+ | +---------------------------+ | | +----------------------+ | +-----------+
| SQLReader +--+ +------+ |
+-----------+ | +---------------------------+ | | +----------------------+ | +-----------+
+-----> Custom DataProcessor +------+------> Custom DataProcessor +--+ +-> SQLWriter |
+---------------------------+ | +----------------------+ | +-----------+
| |
| +----------------------+ |
+---------> Passthrough +-----+
+----------------------+
This Pipeline consists of 4 stages where each DataProcessor is choosing which DataProcessors in the subsequent stage should receive the data it sends. The SQLReader in stage 2, for example, is sending data to only 2 processors in the next stage, while the Custom DataProcessor in stage 2 is sending it's data to 3. The code for constructing and running a Pipeline like this would look like:
// First, initialize all the DataProcessors that will be used in the Pipeline
query1 := processors.NewSQLReader(db1, "SELECT * FROM source_table")
query2 := processors.NewSQLReader(db1, sqlGenerator1) // sqlGenerator1 would be a function that generates the query at run-time. See SQLReader docs.
custom1 := NewCustomDataProcessor1()
query3 := processors.NewSQLReader(db2, sqlGenerator2)
custom2 := NewCustomDataProcessor2()
custom3 := NewCustomDataProcessor3()
passthrough := processors.NewPassthrough()
writeMySQL := processors.NewSQLWriter(db3, "destination_table")
writeCSV := processors.NewCSVWriter(file)
// Next, construct and validate the PipelineLayout. Each DataProcessor
// is inserted into the layout via calls to ratchet.Do().
layout, err := ratchet.NewPipelineLayout(
ratchet.NewPipelineStage(
ratchet.Do(query1).Outputs(query2),
ratchet.Do(query1).Outputs(custom1),
),
ratchet.NewPipelineStage(
ratchet.Do(query2).Outputs(query3, custom3),
ratchet.Do(custom1).Outputs(custom2, custom3, passthrough),
),
ratchet.NewPipelineStage(
ratchet.Do(query3).Outputs(writeCSV),
ratchet.Do(custom2).Outputs(writeCSV),
ratchet.Do(custom3).Outputs(writeCSV),
ratchet.Do(passthrough).Outputs(writeMySQL),
),
ratchet.NewPipelineStage(
ratchet.Do(writeCSV),
ratchet.Do(writeMySQL),
),
)
if err != nil {
// layout is invalid
panic(err.Error())
}
// Finally, create and run the Pipeline
pipeline := ratchet.NewBranchingPipeline(layout)
err = <-pipeline.Run()
This example is only conceptual, the main points being to explain the flexibility you have when designing your Pipeline's layout and to demonstrate the syntax for constructing a new PipelineLayout.
Index ¶
Examples ¶
Constants ¶
This section is empty.
Variables ¶
var StartSignal = "GO"
StartSignal is what's sent to a starting DataProcessor to kick off execution. Typically this value will be ignored.
Functions ¶
func Do ¶
func Do(processor DataProcessor) *dataProcessor
Do takes a DataProcessor instance and returns the dataProcessor type that will wrap it for internal ratchet processing. The details of the dataProcessor wrapper type are abstracted away from the implementing end-user code. The "Do" function is named succinctly to provide a nicer syntax when creating a PipelineLayout. See the ratchet package documentation for code examples of creating a new branching pipeline layout.
Types ¶
type ConcurrentDataProcessor ¶
type ConcurrentDataProcessor interface {
DataProcessor
Concurrency() int
}
ConcurrentDataProcessor is a DataProcessor that also defines a level of concurrency. For example, if Concurrency() returns 2, then the pipeline will allow the stage to execute up to 2 ProcessData() calls concurrently.
Note that the order of data processing is maintained, meaning that when a DataProcessor receives ProcessData calls d1, d2, ..., the resulting data payloads sent on the outputChan will be sent in the same order as received.
type DataProcessor ¶
type DataProcessor interface {
// ProcessData will be called for each data sent from the previous stage.
// ProcessData is called with a data.JSON instance, which is the data being received,
// an outputChan, which is the channel to send data to, and a killChan,
// which is a channel to send unexpected errors to (halting execution of the Pipeline).
ProcessData(d data.JSON, outputChan chan data.JSON, killChan chan error)
// Finish will be called after the previous stage has finished sending data,
// and no more data will be received by this DataProcessor. Often times
// Finish can be an empty function implementation, but sometimes it is
// necessary to perform final data processing.
Finish(outputChan chan data.JSON, killChan chan error)
}
DataProcessor is the interface that should be implemented to perform data-related tasks within a Pipeline. DataProcessors are responsible for receiving, processing, and then sending data on to the next stage of processing.
type Pipeline ¶
type Pipeline struct {
Name string // Name is simply for display purpsoses in log output.
BufferLength int // Set to control channel buffering, default is 8.
PrintData bool // Set to true to log full data payloads (only in Debug logging mode).
// contains filtered or unexported fields
}
Pipeline is the main construct used for running a series of stages within a data pipeline.
func NewBranchingPipeline ¶
func NewBranchingPipeline(layout *PipelineLayout) *Pipeline
NewBranchingPipeline creates a new pipeline ready to run the given PipelineLayout, which can accommodate branching/merging between stages each containing variable number of DataProcessors. See the ratchet package documentation for code examples and diagrams.
Example ¶
package main
import (
"fmt"
"os"
"strings"
"github.com/dailyburn/ratchet"
"github.com/dailyburn/ratchet/data"
"github.com/dailyburn/ratchet/logger"
"github.com/dailyburn/ratchet/processors"
)
func main() {
logger.LogLevel = logger.LevelSilent
// This example is very contrived, but we'll first create
// DataProcessors that will spit out strings, do some basic
// transformation, and then filter out all the ones that don't
// match "HELLO".
hello := processors.NewIoReader(strings.NewReader("Hello world"))
hola := processors.NewIoReader(strings.NewReader("Hola mundo"))
bonjour := processors.NewIoReader(strings.NewReader("Bonjour monde"))
upperCaser := processors.NewFuncTransformer(func(d data.JSON) data.JSON {
return data.JSON(strings.ToUpper(string(d)))
})
lowerCaser := processors.NewFuncTransformer(func(d data.JSON) data.JSON {
return data.JSON(strings.ToLower(string(d)))
})
helloMatcher := processors.NewRegexpMatcher("HELLO")
stdout := processors.NewIoWriter(os.Stdout)
// Create the PipelineLayout that will run the DataProcessors
layout, err := ratchet.NewPipelineLayout(
// Stage 1 - spits out hello world in a few languages
ratchet.NewPipelineStage(
ratchet.Do(hello).Outputs(upperCaser, lowerCaser),
ratchet.Do(hola).Outputs(upperCaser),
ratchet.Do(bonjour).Outputs(lowerCaser),
),
// Stage 2 - transforms strings to upper and lower case
ratchet.NewPipelineStage(
ratchet.Do(upperCaser).Outputs(helloMatcher),
ratchet.Do(lowerCaser).Outputs(helloMatcher),
),
// Stage 3 - only lets through strings that match "hello"
ratchet.NewPipelineStage(
ratchet.Do(helloMatcher).Outputs(stdout),
),
// Stage 4 - prints to STDOUT
ratchet.NewPipelineStage(
ratchet.Do(stdout),
),
)
if err != nil {
panic(err.Error())
}
// Create and run the Pipeline
pipeline := ratchet.NewBranchingPipeline(layout)
err = <-pipeline.Run()
if err != nil {
fmt.Println("An error occurred in the ratchet pipeline:", err.Error())
}
}
Output: HELLO WORLD
func NewPipeline ¶
func NewPipeline(processors ...DataProcessor) *Pipeline
NewPipeline creates a new pipeline ready to run the given DataProcessors. For more complex use-cases, see NewBranchingPipeline.
Example ¶
package main
import (
"fmt"
"os"
"strings"
"github.com/dailyburn/ratchet"
"github.com/dailyburn/ratchet/logger"
"github.com/dailyburn/ratchet/processors"
)
func main() {
logger.LogLevel = logger.LevelSilent
// A basic pipeline is created using one or more DataProcessor instances.
hello := processors.NewIoReader(strings.NewReader("Hello world!"))
stdout := processors.NewIoWriter(os.Stdout)
pipeline := ratchet.NewPipeline(hello, stdout)
err := <-pipeline.Run()
if err != nil {
fmt.Println("An error occurred in the ratchet pipeline:", err.Error())
}
}
Output: Hello world!
func (*Pipeline) Run ¶
Run finalizes the channel connections between PipelineStages and kicks off execution. Run will return a killChan that should be waited on so your calling function doesn't return prematurely. Any stage of the pipeline can send to the killChan to halt execution. Your calling function should check if the sent value is an error or nil to know if execution was a failure or a success (nil being the success value).
type PipelineLayout ¶
type PipelineLayout struct {
// contains filtered or unexported fields
}
PipelineLayout holds a series of PipelineStage instances.
func NewPipelineLayout ¶
func NewPipelineLayout(stages ...*PipelineStage) (*PipelineLayout, error)
NewPipelineLayout creates and validates a new PipelineLayout instance which can be used to create a "branching" Pipeline. A PipelineLayout consists of a series of PipelineStages, where each PipelineStage consists of one or more DataProcessors. See the ratchet package documentation for code examples and diagrams.
This function will return an error if the given layout is invalid. A valid layout meets these conditions:
- DataProcessors in the final PipelineStage must NOT have outputs set.
- DataProcessors in a non-final stage MUST have outputs set.
- Outputs must point to a DataProcessor in the next immediate stage.
- A DataProcessor must be pointed to by one of the previous Outputs (unless it is in the first PipelineStage).
type PipelineStage ¶
type PipelineStage struct {
// contains filtered or unexported fields
}
PipelineStage holds one or more DataProcessor instances.
func NewPipelineStage ¶
func NewPipelineStage(processors ...*dataProcessor) *PipelineStage
NewPipelineStage creates a PipelineStage instance given a series of dataProcessors. dataProcessor (lower-case d) is a private wrapper around an object implementing the public DataProcessor interface. The syntax used to create PipelineLayouts abstracts this type away from your implementing code. For example:
layout, err := ratchet.NewPipelineLayout(
ratchet.NewPipelineStage(
ratchet.Do(aDataProcessor).Outputs(anotherDataProcessor),
// ...
),
// ...
)
Notice how the ratchet.Do() and Outputs() functions allow you to insert DataProcessor instances into your PipelineStages without having to worry about the internal dataProcessor type or how any of the channel management works behind the scenes.
See the ratchet package documentation for more code examples.
 Source Files
¶
Source Files
¶
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
Package data holds custom types and functions for passing JSON between ratchet stages.
|
Package data holds custom types and functions for passing JSON between ratchet stages. |
|
Package logger is a simple but customizable logger used by ratchet.
|
Package logger is a simple but customizable logger used by ratchet. |
|
Package processors contains built-in DataProcessor implementations that are generic and potentially useful across any ETL project.
|
Package processors contains built-in DataProcessor implementations that are generic and potentially useful across any ETL project. |
|
Package util has various helper functions used by components of ratchet.
|
Package util has various helper functions used by components of ratchet. |