 README
¶
README
¶

goharvest



![]()

![]()
Implementation of the Transactional outbox pattern for Postgres and Kafka.
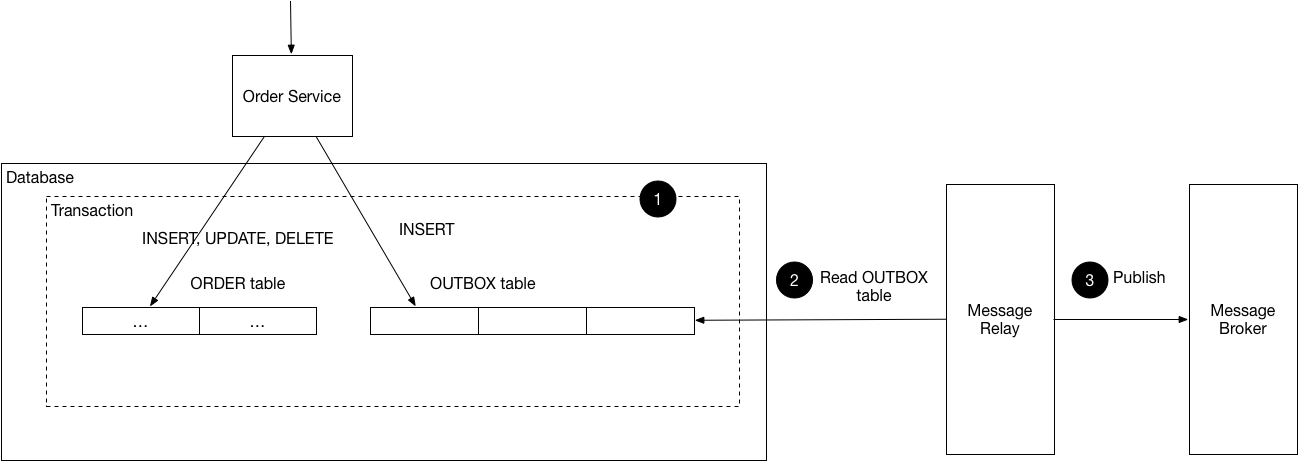 Diagram courtesy of Chris Richardson
Diagram courtesy of Chris Richardson
Considering the diagram above, goharvest plays the role of the Message Relay. It efficiently retrieves records from a relational database (currently Postgres) and publishes them to Kafka. It maintains causal order of records and does not require CDC to be enabled on the database. It handles 5K records/s on low-powered hardware.
How goharvest works
Harvesting of the outbox table sounds straightforward, but there are several notable challenges:
- Contention — although multiple processes may write to a single outbox table (typically, multiple instances of some µ-service), only one process should be responsible for publishing records. Without exclusivity, records may be published twice or out-of-order by contending processes.
- Availability — when one publisher fails, another should take over as soon as possible, with minimal downtime. The failure detection mechanism should be robust with respect to false positives; otherwise, the exclusivity constraint may be compromised.
- Causality — multiple database write operations may be happening concurrently, and some of these operations may be ordered relative to each other. Publishing order should agree with the causal order of insertion. This is particularly challenging as transactions may be rolled back or complete out of order, leaving gaps in identifiers that may or may not eventually be filled.
- At-least-once delivery — ensuring messages are delivered at least once in their lifetime.
- State — the publisher needs to maintain the state of its progress so that it can resume publishing if the process is brought down, or transfer its state over to a new publisher if necessary.
goharvest can be embedded into an existing Go process, or bootstrapped as a standalone application using the reaper CLI. The latter is convenient where the application writing to the outbox is not implemented in Go, in which case reaper can be deployed as a sidecar. goharvest functions identically in both deployment modes; in fact, reaper just embeds the goharvest library, adding some config on top.
Contention and availability
goharvest solves #1 and #2 by using a modified form of the NELI protocol called Fast NELI. Rather than embedding a separate consensus protocol such as PAXOS or Raft, NELI piggy-backs on Kafka's existing leader election mechanism — the one used for electing group and transaction coordinators within Kafka. NELI provides the necessary consensus without forcing the goharvest maintainers to deal with the intricacies of group management and atomic broadcast, and without requiring additional external dependencies.
When goharvest starts, it does not know whether it is a leader or a standby process. It uses a Kafka consumer client to subscribe to an existing Kafka topic specified by Config.LeaderTopic, bound by the consumer group specified by Config.LeaderGroupID. As part of the subscription, goharvest registers a rebalance callback — to be notified of partition reassignments as they occur.
Note: The values
Config.LeaderTopicandConfig.LeaderGroupIDshould be chosen distinctly for each logical group of competing processes, using a name that clearly identifies the application or service. For example,billing-api.
No matter the chosen topic, it will always (by definition) have at least one partition — partition zero. It may carry other partitions too — indexes 1 through to N-1, where N is the topic width, but we don't care about them. Ultimately, Kafka will assign at most one owner to any given partition — picking one consumer from the encompassing consumer group. (We say 'at most' because all consumers might be offline.) For partition zero, one process will be assigned ownership; others will be kept in a holding pattern — waiting for the current assignee to depart or for Kafka to rebalance partition assignments.
Having subscribed to the topic, the client will repeatedly poll Kafka for new messages. Kafka uses polling as a way of verifying consumer liveness. (Under the hood, a Kafka client sends periodic heartbeats, which are tied to topic polling.) Should a consumer stop polling, heartbeats will stop flowing and Kafka's group coordinator will presume the client has died — reassigning partition ownership among the remaining clients. The client issues a poll at an interval specified by Config.Limits.MinPollInterval, defaulting to 100 ms.
The rebalance callback straightforwardly determines leadership through partition assignment, where the latter is managed by Kafka's group coordinator. The use of the callback requires a stable network connection to the Kafka cluster; if a network partition occurs, another client may be granted partition ownership — an event which is not synchronized with the outgoing leader.
Note: While Kafka's internal heartbeats are used to signal client presence to the broker, they are not suitable for the safe handling of network partitions from a client's perspective. During a network partition, the rebalance listener will be invoked at some point after the session times out on the client, by which time the partition may be reassigned on the broker.
In addition to observing partition assignment changes, the owner of partition zero periodically publishes a heartbeat message to Config.LeaderTopic. The client also consumes messages from that topic — effectively observing its own heartbeats, and thereby asserting that it is connected to the cluster and still owns the partition in question. If no heartbeat is received within the period specified by Config.Limits.ReceiveDeadline (5 seconds by default), the leader will take the worst-case assumption that the partition will be reassigned, and will voluntarily relinquish leader status. If connectivity is later resumed while the process is still the owner of the partition on the broker, it will again receive a heartbeat, allowing it to resume the leader role. If the partition has been subsequently reassigned, no heartbeat messages will be received upon reconnection and the client will be forced to rejoin the group — the act of which will invoke the rebalance callback, effectively resetting the client.
Once a goharvest client assumes leader status, it will generate a random UUID named leaderID and will track that UUID internally. Kafka's group coordinator may later choose to reassign the partition to another goharvest client. This would happen if the current leader times out, or if the number of contending goharvest instances changes. (For example, due to an autoscaling event.) Either way, a leadership change is identified via the rebalance callback or the prolonged absence of heartbeats. When it loses leader status, the client will clear the internal leaderID. Even if the leader status is later reverted to a previous leader, a new leaderID will be generated. (The old leaderID is never reused.) In other words, the leaderID is unique across all views of a group's membership state.
The diagram below illustrates the NELI leader election algorithm.
//TODO diagram
Causality, at-least-once delivery and process state
Problems #3, #4 and #5 are collectively solved with one algorithm, which has since been coined mark-purge/reset (MP/R). goharvest requires an outbox table with the following basic structure. (The real table has more columns; the simplified one below is used to illustrate the concept.).
| Column(s) | Type | Unique? | Description |
|---|---|---|---|
| id | serial | yes | A monotonically increasing, database-generated ID. |
| payload | doesn't matter | doesn't matter | One or more columns that describe the contents of the record and how the corresponding message should be published to Kafka. |
| ... | ... | ... | ... |
| leader_id | varchar | no | The unique identifier of the current leader process that marks a record as being in flight. |
In its most basic form, the algorithm operates concurrently across two Goroutines — a mark thread and a purge/reset thread. (Using the term thread for brevity.) Note, the goharvest implementation is significantly more involved, employing a three-stage pipeline with sharding and several concurrent producer clients to maximise throughput. The description here is of the minimal algorithm.
Once leadership has been acquired, the mark thread will begin repeatedly issuing mark queries in a loop, interleaved with periodic polling of Kafka to maintain liveness. Prior to marking, the loop clears a flag named forceRemark. (More on that in a moment.)
A mark query performs two tasks in one atomic operation:
- Identifies the earliest records in the outbox table that either have a
nullleader_id, or have aleader_idvalue that is different from the currentleaderIDof the harvester. This intermediate set is ordered by theidcolumn, and limited in size — so as to avoid long-running queries. - Changes the
leader_idattribute of the records identified in the previous step to the suppliedleaderID, returning all affected records.
Note: Both Oracle and Postgres allow the above to be accomplished efficiently using a single
UPDATE... SET... RETURNINGquery. SQL Server supports a similar query, using theOUTPUTclause. Other databases will require a transaction to execute the above atomically.
The returned records are sorted by id before being processed. Although the query operates on an ordered set internally for the UPDATE clause, the records emitted by the RETURNING clause may be arbitrarily ordered.
Marking has the effect of escrowing the records, tracking the leader's progress through the record backlog. Once the query returns, the marker may enqueue the records onto Kafka. The latter is an asynchronous operation — the records will be sent sometime in the future and, later still, they will be acknowledged on the lead broker(s) and all in-sync replicas. In the meantime, the marking of records may continue (subject to the throttle and barrier constraints), potentially publishing more records as a result. For every record published, the mark thread increments an atomic counter named inFlightRecords, tracking the number of in-flight records. A throttle is applied to the marking process: at most Config.Limits.MaxInFlightRecords may be outstanding before marking is allowed to resume. This value is 1,000 records by default. (See the FAQ for an explanation). In addition to inFlightRecords, a scoreboard named inFlightKeys[key] is used to attribute individual counters for each record key, effectively acting as a synchronization barrier — such that at most one record may exist in flight for any given key. (Explained in the FAQ.)
Note: A scoreboard is a compactly represented map of atomic counters, where a counter takes up a map slot only if it is not equal to zero.
At some point, acknowledgements for previously published records will start arriving, processed by the purge/reset thread. (The combination of the producer client's outbound buffer and asynchronous delivery report handling enables the pipelining of the send and acknowledge operations.) For every acknowledged (meaning it has been durably persisted with Kafka) record, the delivery handler will execute a purge query. This involves deleting the record corresponding to the ID of the acknowledged message. Once a record is deleted, there is no more work to be done for it. The inFlightRecords counter is decremented, and the corresponding inFlightKeys[key] barrier is lowered — permitting the next record to be dispatched for the same key.
Owing to the unreliable nature of networks and I/O devices, there may be an error publishing the record. If an error is identified, we need a way of telling the marking process to re-queue it. This is done using a reset query, clearing the leader_id attribute for the record in question. Having reset the leader ID, we set the forceRemark flag, which was mentioned earlier — signalling to the mark thread that its recently marked records are no longer fit for publishing, in that an older record has since been reinstated. Afterwards, inFlightRecords is decremented and the inFlightKeys[key] barrier is lowered. On the other side, the mark thread will detect this condition upon entering the inFlightKeys[key] barrier, aborting the publishing process and generating a new leader ID. This has the effect of remarking any unacknowledged records, including the recently reset record.
The following diagram illustrates the MP/R algorithm. Each of the numbered steps is explained below.
//TODO diagram.
Key variables
| Variable | Type | Description | Used by |
|---|---|---|---|
leaderID |
UUID |
The currently assigned leader ID | Marker thread |
inFlightRecords |
Atomic int64 counter |
Tracks the number of records sent, for which delivery notifications are still outstanding. | Both threads |
inFlightKeys |
Atomic scoreboard of counters (or bool flags), keyed by a string record key |
Tracks the number of in-flight records for any given record key. Each value can only be 0 or 1 (for integer-based implementations), or false/true for Boolean flags. |
Both threads |
forceRemark |
Atomic bool |
An indication that one or more sent records experienced delivery failures and have been re-queued on the outbox. | Both threads, but only the mark thread may clear it. |
consumer |
Kafka consumer instance | Interface to Kafka for the purpose of leader election. | Marker thread |
producer |
Kafka producer instance | Interface to Kafka for publishing outbox messages | Both threads. The mark thread will publish records; the purge/reset thread will handle delivery notifications. |
On the mark thread...
| Step | Description | ||||
|---|---|---|---|---|---|
| A1 | Check leader status. | ||||
| Condition | Client has leader status (meaning it is responsible for harvesting): | ||||
| A2 | Clear the forceRemark flag, giving the purge/reset thread an opportunity to raise it again, should a delivery error occur. |
||||
| A3 | Invoke the mark query, marking records for the current leaderID and returning the set of modified records. |
||||
| Loop | For each record in the marked batch: | ||||
| A4 | Drain the inFlightRecords counter up to the specified Config.MaxInFlightRecords. |
||||
| A5 | Drain the value of inFlightKeys[key] (where key is the record key), waiting until it reaches zero. At zero, the barrier is effectively lowered, and the thread may proceed. No records for the given key should be in flight upon successful barrier entry. |
||||
| Condition | The forceRemark flag has been not been set (implying that there were no failed delivery reports): |
||||
| A6 | Increment the value of inFlightRecords. |
||||
| A7 | Increment the value of inFlightKeys[key], effectively raising the barrier for the given record key. |
||||
| A8 | Publish the record to Kafka, via the producer client shared among the mark and purge/reset threads. Publishing is asynchronous; messages will be sent at some point in the future, after the send method returns. | ||||
| Condition | The forceRemark flag has been set by the purge/reset thread, implying that at least one failed delivery report was received between now and the time of the last mark. |
||||
| A9 | Refresh the local leaderID by generating a new random UUID. Later, this will have the effect of remarking in-flight records. |
||||
| Until | The forceRemark flag has been set or there are no more records in the current batch. |
||||
On the purge/reset thread...
| Step | Description | ||||
|---|---|---|---|---|---|
| Condition | A message was delivered successfully: | ||||
| B1 | Invoke the purge, removing the outbox record corresponding to the ID of the delivered message. |
||||
| Condition | Delivery failed for a message: | ||||
| B2 | Invoke the query, setting the leader_id attribute of the corresponding outbox record to null. This brings it up on the marker's scope. |
||||
| B3 | Set the forceRemark flag, communicating to the mark thread that at least one record from one of its previous mark cycles could not be delivered. |
||||
| B4 | Decrement the count of inFlightRecords, releasing any active throttles. |
||||
| B5 | Decrement inFlightRecords[key] for the key of the failed record, thereby lowering the barrier. |
||||
| Return from the delivery notification callback. | |||||
Causality is satisfied by observing the following premise:
Given two causally related transactions T0 and T1, they will be processed on the same application and their execution must be serial. Assuming a transaction isolation level of Read Committed (or stricter), their side-effects will also appear in series from the perspective of an observer — the
goharvestmarker. In other words, it may observe nothing (if neither transaction has completed), just T0 (if T1 has not completed), or T0 followed by T1, but never T1 followed by T0. (Transactions here refer to any read-write operation, not just those executing within a demarcated transaction scope.)
Even though marking is always done from the head-end of the outbox table, it is not necessarily monotonic due to the sparsity of records. The marking of records will result in them being skipped on the next pass, but latent effects of transactions that were in flight during the last marking phase may materialise 'behind' the marked records. This is because not all records are causally related, and multiple concurrent processes and threads may be contending for writes to the outbox table. Database-generated sequential IDs don't help here: a transaction T0 may begin before an unrelated T1 and may also obtain a lower number from the sequence, but it may still complete after T1. In other words, T1 may be observed in the absence of T0 for some time, then T0 might appear later, occupying a slot before T1 in the table. This phenomenon is illustrated below.
//TODO diagram
Even though 'gaps' may be filled retrospectively, this only applies to unrelated record pairs. This is not a problem for MP/R because marking does not utilise an offset; it always starts from the top of the table. Any given marking pass will pick up causally-related records in their intended order, while unrelated records may be identified in arbitrary order. (Consult the FAQ for more information on how MP/R compares to its alternatives.) To account for delivery failures and leader takeovers, the use of a per-key barrier ensures that at most one record is in an indeterminate state for any given key at any given time. Should that record be retried for whatever reason — on the same process or a different one — the worst-case outcome is a duplicated record, but not one that is out of order with respect to its successor or predecessor.
State management is simplified because the query always starts at the head-end of the outbox table and only skips those records that the current leader has processed. There is no need to track the offset of the harvester's progress through the outbox table. Records that may have been in-flight on a failed process are automatically salvaged because their leader_id value will not match that of the current leader. This makes MP/R unimodal — it takes the same approach irrespective of whether a record has never been processed or because it is no longer being processed. In other words, there are no if statements in the code to distinguish between routine operation and the salvaging of in-flight records from failed processes.
Getting started
CREATE TABLE outbox (
id BIGSERIAL PRIMARY KEY,
create_time TIMESTAMP WITH TIME ZONE NOT NULL,
kafka_topic VARCHAR(249) NOT NULL,
kafka_key VARCHAR(100) NOT NULL,
kafka_value VARCHAR(10000),
kafka_header_keys TEXT[] NOT NULL,
kafka_header_values TEXT[] NOT NULL,
leader_id UUID
)
Roadmap
- Nullable Kafka (payload) values, to allow for message compaction scenarios.
- Kafka headers.
- MySQL support.
FAQ
Why piggy-back on Kafka for leader election?
The piggy-backing approach using simplified NELI is one option. Another approach is the use of an external Group Management Service (GMS) or, more likely, a Distributed Lock Manager (DLM) which is built on top of a GMS specifically for arbitrating leadership among contending processes.
A DLM/GMS, such as Consul, Etcd, Chubby or ZooKeeper, is an appropriate choice in many cases. A point raised by the NELI paper (and the main reason for its existence) is that infrastructure may not be readily available to provide this capability. Further to that point, someone needs to configure and maintain this infrastructure, and ensure its continuous availability — otherwise it becomes a point of failure in itself. This problem is exacerbated in a µ-services architecture, where it is common-practice for services to own their dependencies. Should DLMs be classified as service-specific dependencies, or should they be shared? Either approach has its downsides.
The NELI approach is particularly attractive where the middleware used by applications for routine operation can also be employed in a secondary role for deriving leader state. There are no additional dependencies to maintain; everything one needs is at hand.
An alternate approach that does not require external dependencies is to use the database (that hosts the outbox table) to arbitrate leadership. This can be achieved using a simple, timestamp-based lease protocol. Contending processes collectively attempt to set a common field in a table, using transaction scope to ensure that only one of the contending processes succeeds. Other processes will back off, waiting for the lease to expire. If the leader is alive, it can renew the lease; otherwise, it will fall onto one of the competing processes to take over the lease.
The lease algorithm is a simple and robust way of achieving consensus within a process group, using a centralised service that is already at their disposal. One of its drawbacks is that contention requires continuous querying of the database by all processes. This querying is in addition to the harvesting of the outbox table. As the group grows in size, the load on the database increases, making the lease model less scalable. Another drawback is that the best-case failure detection period equates to the lease interval. In other words, if a process acquires a lease and fails, no other process can step in until the lease period elapses.
By comparison, NELI does not place additional load on the database. Leader election is done via Kafka; once a leader is elected, only that process accesses the database. There are no assumptions made as to the scalability needs of applications utilising goharvest — it is designed to work equally well for tiny deployments, as well as for massive clusters — provided Kafka is appropriately sized. (A relational database is not designed to scale horizontally, and must be viewed as a scarce resource. By comparison, Kafka was designed for horizontal scalability from the outset.)
Failure detection is also more responsive. If a process fails or experiences a network partition, the group coordinator (a component within Kafka) will detect the absence of heartbeats and will initiate a group rebalance. This is configured by the session.timeout.ms consumer property, which is ten seconds by default. If the process departs gracefully, closing its Kafka connections in an orderly manner, the partition rebalance will occur sooner.
Q: Why should I change the default leader topic and group ID?
The Config.LeaderTopic and Config.LeaderGroupID must be shared among contending application instances and must also be unique outside that group. As such, goharvest uses the name of the application's executable binary, which works out reasonably well most of the time, provided applications are well named; for example, bin/billing-api rather than bin/api.
The default value unravels when using a debugger such as Delve, which generates a file named __debug_bin. Unless Config.LeaderGroupID is set, anyone who is debugging their Go application will end up sharing the same group ID.
Q: Can Kubernetes be used to solve the contention and availability problems?
As a control system for arbitrating service resources and ensuring their continued availability, Kubernetes is indispensable. However, it doesn't offer a robust solution for ensuring process exclusivity — this is not its purpose. Limiting the maximum number of replicas to 1 does not ensure that at most one replica is live — a new pod may be launched as part of a deployment, while taking over the traffic from an existing one — running side by side. Also, if one of the containers in a pod fails a health check, it will be summarily replaced; however, during the transition period, the failed pod may be running alongside its replacement.
Q: Why throttle the total number of in-flight records?
Limiting the number of in-flight records minimises the memory pressure on the client (as records are queued in an in-memory buffer before being forwarded to the broker). This method of flow control transfers the buffering responsibility to the database, reducing the memory footprint of the goharvest client.
Q: Why throttle in-flight records by key?
Messages are generally published in batches for efficiency, which is particularly crucial in high-latency networks (where Kafka is not collocated with the application deployment). One of the challenges of enqueuing multiple messages relates to the prospect of observing intermittent errors, where those errors may affect a part of the transmission. (The producer client splits the backlog of queued messages into multiple batches under the hood; some batches may fail in isolation, while others may succeed.) Under the naive model of sending all marked messages, causality is only respected when there are no I/O errors during publishing. Given causally related records R0, R1 and R2, and the asynchronous nature of publishing messages, it is conceivable that R0 might succeed, R1 might fail, while R2 might again succeed. The harvester would detect the error for R1, by which time it may be too late — R2 may already have been persisted on the broker. Retrying R1 (assuming it will eventually succeed) will result in records appearing out of order; specifically, R0, R2, R1.
A related condition is where an existing leader process fails, having a batch of messages in flight. (Messages sent to the broker, where an acknowledgement is pending.) The new leader will re-mark the in-flight records, scavenging the workload of the outgoing leader. It will then send records again, being unaware of their previous status. This may result not only in one-off record duplication, but duplication of a contiguous sequence of records; for example, R0, R1, R2, R0, R1, R2. The mid-point of the sequence, where R0 follows R2, is unacceptable — it constitutes order reversal. Conversely, one-off duplication, such as the sequence R0, R1, R1, R2 is acceptable; while suboptimal, duplicate message delivery is an inherent characteristic of messaging systems that are based around at-least-once delivery patterns.
MP/R deals with this problem by constraining not only the total number of in-flight records, but the number of records in flight for any given key. Because causality in Kafka is captured via a record's key, ensuring that at most one message is in an indeterminate state solves both the issue of I/O errors and abrupt leadership changes.
In the absence of the per-key scoreboard, this would have to be addressed by changing the normally asynchronous nature of the mark-purge/reset pipeline to behave fully synchronously. This would involve setting Config.MaxInFlightRecords to 1, effectively annulling the MP/R pipeline. The throughput would drop significantly and, crucially, becomes tied to the round-trip latency of a single Kafka write call. The performance would correspondingly drop by several orders of magnitude. By utilising a scoreboard, MP/R maintains high throughput, provided the keys are reasonably distributed. (Conversely, if records are clustered around a small set of unique keys, the throughput will degrade considerably; but this would effect any algorithm that maintains partial order.)
Q: What about tailing?
Broadly speaking, there are two ways one can harvest an outbox:
- Tailing — using a separate Change Data Capture (CDC) facility to identify new outbox records as they come in.
- Scraping — inferring the changes by analysing the contents of the outbox table.
goharvestlies in this category.
It must be acknowledged that, in some ways, tailing is ideally suited to the problem. CDC presents data in the order they were committed, rather than the order in which the sequence numbers were assigned. There are no gaps and the audit records and queries are straightforward.
While it appears straightforward on the surface, there are several challenges inherent in CDC:
- CDC is not portable. Not all databases support CDC, and those that do might not offer CDC capability on managed offerings. For example, AWS offers CDC on conventional RDS, but not Aurora. Google Cloud SQL does not offer CDC at all. (Log-based CDC requires parsing of the database Write-Ahead Log, which means additional software must be running on each database server node.)
- Due to the asynchronous nature of publishing and the prospect of failures, we need to store a delivery state for each outbox record. Depending on how CRC is implemented, this may not be trivial.
- For example, log-based CRC in Postgres does not present data in a table; instead, it uses a stream that may be queried like a table, using a SQL-like syntax. The state data may need to be persisted in a separate table, or alternatively, the tailer may limit itself to peeking into the stream, and only retrieve records when acknowledgements have been received. This makes it harder to implement pipelining, as in-flight records will appear when peeking into a CDC stream.
- Trigger-based CDC is easier to work with, as it writes to a dedicated, long-lived table. On the flip side, trigger-based CDC is inefficient, impacting the write transaction.
- Log-based CDC is not enabled at the database, but at the master node. (This is the case for Postgres; others may differ.) If a failover occurs, logical replication must be explicitly re-enabled on the new active node. The failover event may not be apparent to the application, particularly when using a Cloud-based service. Trigger-based CDC does not suffer from this approach, but is markedly less efficient than the log-based model.
By all accounts, when it comes to harvest an outbox, scraping is doing it the 'hard way'. This path was chosen because, while it is harder on goharvest, it is easier on the user — create the outbox table and fire away. No portability issues and no menial DBA work. Also, MP/R does not impact update performance for applications logging to the outbox — there are no triggers on the commit path. Finally, while goharvest is presently limited to Postgres, there is a strong desire to support other relational databases, which makes proprietary CDC solutions less tractable.
Q: What are some of the other approaches?
Tailing the outbox using offset-based queries
Anecdotally, most scrapers keep track of their offset in the outbox — the sequential ID of the last row returned by a polling query. The next query uses this as the offset. Typically, this is implemented using Kafka Connect, which takes care of contention, availability and state management.
This approach is prone to skipping over records as a result of out-of-order transactions. Often, this is not caught in development, where the traffic volume is insufficient to induce this condition. Fundamentally, Kafka Connect is designed for reading monotonic CDC audit tables, not for scraping an outbox. This is not common knowledge; there is a low-key discussion on Stack Overflow that touches on this. Nonetheless, judging by the Internet chatter, this appears to be the most common initial implementation. (At least until the problems begin to emerge.)
Tailing the outbox using time-based queries
Once the problem with the above approach is identified, the go-to fix is typically to allow for a grace period for latent records, rather than relying solely on sequential IDs. Effectively, each subsequent query trails the time of the oldest record returned by the last query by a fixed period — in the order of seconds or minutes. The challenge here is to find a suitable grace period, such that it is generous enough to account for the longest-running transactions, yet not so generous that it blows out the query. Taking this route implies dropping Kafka Connect in favour of a custom scraper, which means all of a sudden having to deal with contention and availability. This means using an atomic broadcast protocol or a distributed lock service built on top of one, or alternatively, using the database itself as a centralised lock store. NELI is another option.
Looking for discontinuities
A variation of the two approaches above, this tactic recognises that gaps in ID sequences are possible, but are relatively infrequent — caused by rollbacks or otherwise failed writes.
Instead of querying by time, this approach starts off by optimistically querying by a starting ID, advancing linearly for as long as the returned IDs are densely populated. If sparsity is detected, the model pins the starting offset to the point of the observed discontinuity. Naturally, it cannot wait forever, so a grace period is accorded – after which the offset starts advancing again.
The challenge with this approach is the complexity of the implementation, being bimodal in nature — requiring special treatment of gaps. It can also be stalled by discontinuities that take a long time to resolve (such as long-running transactions) or are never resolved (for example, rollbacks). When these events occur, the harvester will 'stutter', creating undue lag in outbox message delivery.
Read uncommitted queries
The non-monotonic nature of outbox queries is owed largely to transaction isolation. Remove isolation on the harvester (by setting it connection to Read Uncommitted), and transaction side-effects become immediately observable.
This approach is unsuitable for several reasons:
- It does not support rollbacks. Once the effects of a transaction have been observed, they cannot be revoked. Even if the outbox write is the last statement in a transaction, there is still a remote likelihood of a rollback in databases that support MVCC, such as Oracle and Postgres.
- While dirty reads might appear to be monotonic, there is (at least) one case where they are not. Specifically, the atomic allocation of numbers from a sequence is independent of that number being subsequently used. It is possible for T0 to acquire a smaller number that T1, but for T1 to use its acquired number to insert a row first, thereby appearing sooner than T0 to an observer and leaving a gap in the sequence. T0 may appear a split second later to fill the gap, at which point the query may have already advanced past that point.
- Postgres does not support Read Uncommitted; the lowest isolation level is Repeatable Read.
Last updated timestamp
Database-assigned timestamps are used to efficiently identify records that have been changed. Because time only runs forward, especially when it is sampled from a centralised source, there is a misconception that time-based predicates are inherently monotonic. They are not, for the following reasons:
- The monotonicity of the underlying time source depends on a range of factors that are outside of our control, such as the operating system, the presence of a hypervisor, the use of NTP, and the database implementation itself. As it stands, Postgres uses the real-time clock today, which is not monotonic. (It may appear to run backwards under some circumstances.)
- Under Read Committed isolation, transaction side-effects may be observed out of order.
- Postgres serves each database connection out of a dedicated POSIX thread. When two queries are issued on different connections, the two may return mutually-unordered timestamps, due to the behaviour of
clock_gettime(CLOCK_REALTIME,...)across multiple OS-level threads.
Synchronous batching
An alternative approach to time-based querying is to drop the pipeline and process records one batch at a time. In other words, read a batch of records, write to Kafka, await confirmations, delete the records (or mark them as done), then repeat — always reading from the head (not dissimilar to MP/R). A straightforward model that is bulletproof, owing largely to the simplicity of not having to manage individual record state — we implicitly know which records are in flight because we are blocked on them.
While state management is simplified, the process still needs to account for contention and availability. A notable drawback of this approach is its blocking nature. While a batch is being processed and the scraper waits for acknowledgements from the brokers, pending outbox records are held up. The lack of pipelining means it can only do one thing — either query and publish records, await confirmations, or update its state.
Monotonic tailing of the outbox using transaction IDs
One of the most elaborate solutions for monotonic table reads was presented by Leigh Brenecki in Efficiently fetching updated rows with Postgres. In summary, it injects a monotonically increasing internal transaction ID into each record, using a trigger function. Subsequent SELECT queries locate the oldest transaction that is currently active and use it as a predicate for filtering records. In this manner, the query acts like a sliding window — advancing only when the oldest transaction commits or rolls back. This technique is Postgres-specific; other databases may permit similar queries, but due to their proprietary nature, each is likely to differ substantially.
Briefly, there are several challenges with Brenecki's approach:
- Triggers impact insert/update performance.
- Assuming a
LIMITclause is in place (as it should be), a long-running transaction will stall the value returned bytxid_snapshot_xmin(txid_current_snapshot()). The harvester will not see records beyond its query window until the late-running transaction completes. In the meantime, there may be multiple short-running transactions that would have deposited records into the outbox; they will not be processed until the window advances. - Postgres transaction IDs are 32-bit counters padded to a 64-bit integer. They are recycled after approximately 4B transactions, causing a discontinuity in the number sequence.
There is a known variation of this model that uses commit timestamps instead of transaction IDs. It has similar limitations, with the exception of the txid recycling issue.
Application-level diff
This model applies pipelining to the previous model. Records may be read and published independently of receiving confirmations. The issue here is that the poll query returns both pending and in-flight records. We need to discern among them, otherwise records will be published in duplicate. So the scraper keeps track of all previously read records and filters them out of the query's result set. Because queries can get quite large, this model significantly limits the number of records that may be in-flight, making it harder to scale under high-latency broker connections, where the number of in-flight records must increase to allow for reasonable throughput.
Relationship to MP/R
Of the approaches outlined, application-level diff is the closest relative of MP/R. The main difference is that MP/R does not track in-flight records in memory — it only keeps their count for throttling purposes, which does not functionally affect the algorithm. The in-flight tracking is accomplished by atomically 'marking' the leader_id on each record as soon as it has been read, which doubles as a predicate for the subsequent query. Marking is the database equivalent of the compare-and-swap instruction, used to implement synchronization primitives in multithreaded systems. A mark only returns those records that are either pending, or have been left in an indeterminate state by a failed harvester; having returned those rows, it atomically excludes these records from subsequent queries, for as long as the same leader ID is maintained.
It may appear that MP/R should not need to rely on the atomicity of the marking process, as marking is performed on a dedicated thread that is uncontended — owing to the overarching leader election process curated by NELI. And that is, indeed, the case. However, if the query were not atomic, we would need a way knowing which records were marked, as a plain UPDATE statement only returns the number of affected rows. In the absence of atomicity, the easiest way is to assign a unique identifier as part of each UPDATE, then perform a follow-up SELECT with the same identifier as its WHERE predicate.
In addition to acting as a synchronization primitive, the atomicity property is useful in eliminating multiple round-trips and index traversals. A single UPDATE...RETURNING clause employs one index traversal to locate the candidate records, update them, and return them in a result set.
MP/R requires one read and two writes for each outbox record. By comparison, application-level diff gets away with one read and one write. On the flip side, the read queries are larger. Because a query returns both pending and in-flight records, the limit of the query is the maximum number of in-flight records. By contrast, MP/R supports small, incremental queries that are uncorrelated to the in-flight limit. To appreciate the difference, consider a scenario where the harvester is configured with an in-flight limit of 1,000 records, and is currently sitting on a full backlog. It may safely stop polling to save database I/O. As soon as an acknowledgement arrives for the oldest record, the backlog drops to 999 records and the record is struck out. It can now poll the database again. But here is the snag: it must query for another 1,000 records despite only having one transmit slot available — it doesn't have a way of querying for just the new records. It cannot simply use the offset of the most recent enqueued record as the starting point, owing to the non-monotonic nature of the outbox.
In summary
The descriptions above are just some of the tactics that have been employed by the industry to scrape database tables, not just for implementing a transactional outbox, but for general-purpose replication scenarios. Likely, each has several variations, plus a host of proprietary tactics for specific database servers. This is not a trivial problem, and will likely require several attempts to get right.
The main objective behind goharvest was to create a working model that is straightforward to use and reasonably performant. Unencumbered of proprietary techniques, it may be adapted to other database technologies and partially ordered event streaming brokers in the future.
Q: Why didn't you use a native Go Kafka library?
There are two mainstream native Go libraries: Segment.io and Serama. Both have similar limitations that would complicate the harvester implementation:
- No rebalance notifications. The libraries support group-based assignment of partitions, but do not inform the application when partitions have been assigned or revoked. We piggy-back on Kafka for leader election, which is more difficult (but not impossible) to achieve when the client library is not forwarding partition assignment changes. (See the NELI paper on how this can be done in the absence of notifications.)
- Lack of fine-grained delivery reports. When using the asynchronous API, there is no notification of a successful or failed message delivery — which is needed for the purge/reset operation. The synchronous API can report errors, but only if messages are sent one at a time, which is inefficient, especially over high-latency links. When batching messages, it is not possible to determine which of the messages could not be sent.
 Documentation
¶
Documentation
¶
Overview ¶
Example ¶
const dataSource = "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable"
// Optional: Ensure the database table exists before we start harvesting.
func() {
db, err := sql.Open("postgres", dataSource)
if err != nil {
panic(err)
}
defer db.Close()
_, err = db.Exec(`
CREATE TABLE IF NOT EXISTS outbox (
id BIGSERIAL PRIMARY KEY,
create_time TIMESTAMP WITH TIME ZONE NOT NULL,
kafka_topic VARCHAR(249) NOT NULL,
kafka_key VARCHAR(100) NOT NULL, -- pick your own key size
kafka_value VARCHAR(10000), -- pick your own value size
kafka_header_keys TEXT[] NOT NULL,
kafka_header_values TEXT[] NOT NULL,
leader_id UUID
)
`)
if err != nil {
panic(err)
}
}()
// Configure the harvester. It will use its own database connections under the hood.
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
DataSource: dataSource,
}
// Create a new harvester.
harvest, err := New(config)
if err != nil {
panic(err)
}
// Start it.
err = harvest.Start()
if err != nil {
panic(err)
}
// Wait indefinitely for it to end.
log.Fatal(harvest.Await())
Example (WithCustomLogger) ¶
// Example: Configure GoHarvest with a Logrus binding for Scribe.
log := logrus.StandardLogger()
log.SetLevel(logrus.DebugLevel)
// Configure the custom logger using a binding.
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
Scribe: scribe.New(scribelogrus.Bind()),
DataSource: "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable",
}
// Create a new harvester.
harvest, err := New(config)
if err != nil {
panic(err)
}
// Start it.
err = harvest.Start()
if err != nil {
panic(err)
}
// Wait indefinitely for it to end.
log.Fatal(harvest.Await())
Example (WithEventHandler) ¶
// Example: Registering a custom event handler to get notified of leadership changes and metrics.
log := logrus.StandardLogger()
log.SetLevel(logrus.TraceLevel)
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9092",
},
DataSource: "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable",
Scribe: scribe.New(scribelogrus.Bind()),
}
// Create a new harvester and register an event hander.
harvest, err := New(config)
if err != nil {
panic(err)
}
harvest.SetEventHandler(func(e Event) {
switch event := e.(type) {
case LeaderAcquired:
log.Infof("Got event: leader acquired: %v", event.LeaderID())
case LeaderRefreshed:
log.Infof("Got event: leader refreshed: %v", event.LeaderID())
case LeaderRevoked:
log.Infof("Got event: leader revoked")
case LeaderFenced:
log.Infof("Got event: leader fenced")
case *MeterRead:
log.Infof("Got event: meter read: %v", event.Stats())
}
})
// Start harvesting.
err = harvest.Start()
if err != nil {
panic(err)
}
// Wait indefinitely for it to end.
log.Fatal(harvest.Await())
Example (WithSaslSslAndCustomProducerConfig) ¶
// Example: Using Kafka with sasl_ssl for authentication and encryption.
config := Config{
BaseKafkaConfig: KafkaConfigMap{
"bootstrap.servers": "localhost:9094",
"security.protocol": "sasl_ssl",
"ssl.ca.location": "ca-cert.pem",
"sasl.mechanism": "SCRAM-SHA-512",
"sasl.username": "alice",
"sasl.password": "alice-secret",
},
ProducerKafkaConfig: KafkaConfigMap{
"compression.type": "lz4",
},
DataSource: "host=localhost port=5432 user=postgres password= dbname=postgres sslmode=disable",
}
// Create a new harvester.
harvest, err := New(config)
if err != nil {
panic(err)
}
// Start it.
err = harvest.Start()
if err != nil {
panic(err)
}
// Wait indefinitely for it to end.
log.Fatal(harvest.Await())
Index ¶
- func Duration(d time.Duration) *time.Duration
- func Int(i int) *int
- func StringPtr(str string) *string
- type Config
- type DatabaseBinding
- type DatabaseBindingProvider
- type Event
- type EventHandler
- type Harvest
- type KafkaConfigMap
- type KafkaConsumer
- type KafkaConsumerProvider
- type KafkaHeader
- type KafkaHeaders
- type KafkaProducer
- type KafkaProducerProvider
- type LeaderAcquired
- type LeaderFenced
- type LeaderRefreshed
- type LeaderRevoked
- type Limits
- type MeterRead
- type NeliProvider
- type OutboxRecord
- type State
Examples ¶
Constants ¶
This section is empty.
Variables ¶
This section is empty.
Functions ¶
Types ¶
type Config ¶
type Config struct {
BaseKafkaConfig KafkaConfigMap `yaml:"baseKafkaConfig"`
ProducerKafkaConfig KafkaConfigMap `yaml:"producerKafkaConfig"`
LeaderTopic string `yaml:"leaderTopic"`
LeaderGroupID string `yaml:"leaderGroupID"`
DataSource string `yaml:"dataSource"`
OutboxTable string `yaml:"outboxTable"`
Limits Limits `yaml:"limits"`
KafkaConsumerProvider KafkaConsumerProvider
KafkaProducerProvider KafkaProducerProvider
DatabaseBindingProvider DatabaseBindingProvider
NeliProvider NeliProvider
Scribe scribe.Scribe
Name string `yaml:"name"`
}
Config encapsulates configuration for Harvest.
func Unmarshal ¶
Unmarshal a configuration from a byte slice, returning the configuration struct with pre-initialised defaults, or an error if unmarshalling failed. The configuration is not validated prior to returning, in case further amendments are required by the caller. The caller should call Validate() independently.
func (*Config) SetDefaults ¶
func (c *Config) SetDefaults()
SetDefaults assigns the default values to optional fields.
type DatabaseBinding ¶
type DatabaseBinding interface {
Mark(leaderID uuid.UUID, limit int) ([]OutboxRecord, error)
Purge(id int64) (bool, error)
Reset(id int64) (bool, error)
Dispose()
}
func NewPostgresBinding ¶
func NewPostgresBinding(dataSource string, outboxTable string) (DatabaseBinding, error)
type DatabaseBindingProvider ¶
type DatabaseBindingProvider func(dataSource string, outboxTable string) (DatabaseBinding, error)
func StandardPostgresBindingProvider ¶
func StandardPostgresBindingProvider() DatabaseBindingProvider
type EventHandler ¶
type EventHandler func(e Event)
EventHandler is a callback function for handling GoHarvest events.
type Harvest ¶
type Harvest interface {
Start() error
Stop()
Await() error
State() State
IsLeader() bool
LeaderID() *uuid.UUID
InFlightRecords() int
InFlightRecordKeys() []string
SetEventHandler(eventHandler EventHandler)
}
Harvest performs background harvesting of a transactional outbox table.
type KafkaConfigMap ¶
type KafkaConfigMap map[string]interface{}
KafkaConfigMap represents the Kafka key-value configuration.
type KafkaConsumer ¶
type KafkaConsumer interface {
Subscribe(topic string, rebalanceCb kafka.RebalanceCb) error
ReadMessage(timeout time.Duration) (*kafka.Message, error)
Close() error
}
KafkaConsumer specifies the methods of a minimal consumer.
type KafkaConsumerProvider ¶
type KafkaConsumerProvider func(conf *KafkaConfigMap) (KafkaConsumer, error)
KafkaConsumerProvider is a factory for creating KafkaConsumer instances.
func StandardKafkaConsumerProvider ¶
func StandardKafkaConsumerProvider() KafkaConsumerProvider
StandardKafkaConsumerProvider returns a factory for creating a conventional KafkaConsumer, backed by the real client API.
type KafkaHeader ¶
func (KafkaHeader) String ¶
func (h KafkaHeader) String() string
type KafkaHeaders ¶
type KafkaHeaders []KafkaHeader
type KafkaProducer ¶
type KafkaProducer interface {
Events() chan kafka.Event
Produce(msg *kafka.Message, deliveryChan chan kafka.Event) error
Close()
}
KafkaProducer specifies the methods of a minimal producer.
type KafkaProducerProvider ¶
type KafkaProducerProvider func(conf *KafkaConfigMap) (KafkaProducer, error)
KafkaProducerProvider is a factory for creating KafkaProducer instances.
func StandardKafkaProducerProvider ¶
func StandardKafkaProducerProvider() KafkaProducerProvider
StandardKafkaProducerProvider returns a factory for creating a conventional KafkaProducer, backed by the real client API.
type LeaderAcquired ¶
type LeaderAcquired struct {
// contains filtered or unexported fields
}
LeaderAcquired is emitted upon successful acquisition of leader status.
func (LeaderAcquired) LeaderID ¶
func (e LeaderAcquired) LeaderID() uuid.UUID
LeaderID returns the local UUID of the elected leader.
func (LeaderAcquired) String ¶
func (e LeaderAcquired) String() string
String obtains a textual representation of the LeaderAcquired event.
type LeaderFenced ¶
type LeaderFenced struct{}
LeaderFenced is emitted when the leader status has been revoked.
func (LeaderFenced) String ¶
func (e LeaderFenced) String() string
String obtains a textual representation of the LeaderFenced event.
type LeaderRefreshed ¶
type LeaderRefreshed struct {
// contains filtered or unexported fields
}
LeaderRefreshed is emitted when a new leader ID is generated as a result of a remarking request.
func (LeaderRefreshed) LeaderID ¶
func (e LeaderRefreshed) LeaderID() uuid.UUID
LeaderID returns the local UUID of the elected leader.
func (LeaderRefreshed) String ¶
func (e LeaderRefreshed) String() string
String obtains a textual representation of the LeaderRefreshed event.
type LeaderRevoked ¶
type LeaderRevoked struct{}
LeaderRevoked is emitted when the leader status has been revoked.
func (LeaderRevoked) String ¶
func (e LeaderRevoked) String() string
String obtains a textual representation of the LeaderRevoked event.
type Limits ¶
type Limits struct {
IOErrorBackoff *time.Duration `yaml:"ioErrorBackoff"`
PollDuration *time.Duration `yaml:"pollDuration"`
MinPollInterval *time.Duration `yaml:"minPollInterval"`
MaxPollInterval *time.Duration `yaml:"maxPollInterval"`
HeartbeatTimeout *time.Duration `yaml:"heartbeatTimeout"`
DrainInterval *time.Duration `yaml:"drainInterval"`
QueueTimeout *time.Duration `yaml:"queueTimeout"`
MarkBackoff *time.Duration `yaml:"markBackoff"`
MaxInFlightRecords *int `yaml:"maxInFlightRecords"`
SendConcurrency *int `yaml:"sendConcurrency"`
SendBuffer *int `yaml:"sendBuffer"`
MarkQueryRecords *int `yaml:"markQueryRecords"`
MinMetricsInterval *time.Duration `yaml:"minMetricsInterval"`
}
Limits configuration.
func (*Limits) SetDefaults ¶
func (l *Limits) SetDefaults()
SetDefaults assigns the defaults for optional values.
type MeterRead ¶
type MeterRead struct {
// contains filtered or unexported fields
}
MeterRead is emitted when the internal throughput Meter has been read.
func (MeterRead) Stats ¶
func (e MeterRead) Stats() metric.MeterStats
Stats embedded in the MeterRead event.
type NeliProvider ¶
NeliProvider is a factory for creating Neli instances.
func StandardNeliProvider ¶
func StandardNeliProvider() NeliProvider
StandardNeliProvider returns a factory for creating a conventional Neli instance, backed by the real client API.
type OutboxRecord ¶
type OutboxRecord struct {
ID int64
CreateTime time.Time
KafkaTopic string
KafkaKey string
KafkaValue *string
KafkaHeaders KafkaHeaders
LeaderID *uuid.UUID
}
func (OutboxRecord) String ¶
func (rec OutboxRecord) String() string