 README
¶
README
¶
# Шаблон backend сервера на Golang — часть 5 - оптимизация Worker pool
Пятая часть посвящена оптимизации Worker pool и особенностям его работы в составе микросервиса, развернутого в Kubernetes.
Представленный Worker pool поддерживает работу с двумя типами задач
- "Короткие" - не контролируется предельный timeout выполнения и их нельзя прервать
- "Длинные" - контролируется предельный timeout выполнения и их можно прервать
Накладные расходы Worker pool на добавление в очередь, контроль очереди, запуск обработки task, контроль времени выполнения task:
- Для "коротких" task - от 300 ns/op, 0 B/op, 0 allocs/op
- Для "длинных" task - от 1400 ns/op, 16 B/op, 1 allocs/op
Для task, которые должны выполняться быстрее 200 ns/op представленный Worker pool использовать не эффективно
Собираются следующие метрики prometheus:
- wp_worker_process_count_vec - количество worker в работе
- wp_task_process_duration_ms_by_name - гистограмма длительности выполнения task в ms с группировкой по task.name
- wp_task_queue_buffer_len_vec - текущая длина канала-очереди task - показывает заполненность канала
- wp_add_task_wait_count_vec - количество задач, ожидающих попадания в очередь
Ссылка на репозиторий проекта.
Шаблон goapp в репозитории полностью готов к развертыванию в Docker, Docker Compose, Kubernetes (kustomize), Kubernetes (helm).
Ссылки на предыдущие части:
- Первая часть шаблона была посвящена HTTP серверу.
- Вторая часть шаблона была посвящена прототипированию REST API.
- Третья часть посвящена развертыванию шаблона в Docker, Docker Compose, Kubernetes (kustomize).
- Четвертая часть будет посвящена развертыванию в Kubernetes с Helm chart и настройке Horizontal Autoscaler.
Содержание
- Особенности работы worker pool в составе микросервиса в Kubernetes
- Архитектура Worker pool
- Структура Task
- Структура Worker
- Структура Pool
- Оптимизация Worker pool
- Нагрузочное тестирование Worker pool
- Профилирование Worker pool
1. Особенности работы worker pool в составе микросервиса в Kubernetes
При развертывании приложения в Kubernetes столкнулись с такими особенностями.
- при росте нагрузки Horizontal Autoscaler (HA) может создавать новые Pod c приложением и перенаправлять на него часть запросов.
- при снижении нагрузки (по памяти или загрузке процессора), Horizontal Autoscaler останавливает Pod c приложением.
В нашем приложении Worker pool, использовался для двух типов задач:
- "Короткие" - 100-500 mc - высоконагруженные расчеты
- "Длинные" - выполнялись 1-30 s, обычно - это слабонагруженные задачи взаимодействия с внешними сервисами. Сервисы-потребители таких "длинных" task могут быть асинхронными.
В периоды высокой нагрузки, Horizontal Autoscaler создавал 2-5 новых Pod, а через 30-60 минут удалял ненужные. Pod останавливаются произвольным образом, в результате мы получали обрывы соединений и отказ в обслуживании для длительных операции.
Правильный вариант решения такой проблемы - это разнесение разных типов задач на разные микросервисы.
Но вместе с этим, пришлось серьезно перепроектировать Worker pool для корректной остановки и оптимизации памяти и cpu.
Условно, можно выделить следующие подходы к остановке Worker pool:
- "Light" - все начатые к обработке и все взятые в очередь задачи должны быть завершены, новые задачи не принимаются. Потребители по новым запросам получают отказ в обслуживании.
- "Soft" - только начатые к обработке задачи должны быть завершены, новые задачи не принимаются, оставшиеся в очереди задачи останавливаются с ошибкой. Потребители по новым запросам и запросам не начатым обрабатываться получают отказ в обслуживании.
- "Soft + timeout" - сначала отрабатывает "Soft", если не уложились в timeout, то срабатывает "Hard".
- "Hard" - экстренно прерывается обработка всех задач, как начатых, так и находящихся в очереди. Потребители получают отказ в обслуживании.
- "Crash" - приложение удаляется KILL -9. Сетевые соединения разрываются. Потребители не получают дополнительной информации кроме разрыва соединения.
Если приложение stateless, то, желательно использовать подход "Crash" или "Hard". Потребители всегда смогут отправить повторные запросы и их обработает другой Pod.
Если приложение stateful, и завершить начатые задачи в режиме "soft" невозможно, то нужно сделать пометку о необходимости компенсационного действия. Компенсационные действия может выполнять само приложение при повторном запуске, либо отдельный служебный сервис.
Шаблон Worker pool в репозитории поддерживается варианты остановки "Light", "Soft", "Soft + timeout", "Hard". по умолчанию настроен режим "Soft + timeout".
2. Архитектура Worker pool
В основе Worker pool лежит концепция из статьи Ahad Hasan.
- task - содержит входные параметры задачи, функцию обработчик, результаты выполнения, каналы для управления и таймер для контроля timeout.
- worker - контролирует очередь задач выполняет task в своей goroutine
- pool - содержит очередь задач, создает worker и мониторит их статус, управляет процессом остановки
Основные задачи Task:
- Запустить функцию-обработчик и передать ей входные данные
- Контролировать результат выполнения функции-обработчика
- Информировать "внешний мир" о завершении выполнения функции-обработчика
- Контролировать время выполнения функции-обработчика по timeout, при необходимости прервать выполнение
- Перехватить panic от функции-обработчика и обработать ошибку
- Контролировать команду на остановку со стороны Worker pool
- Информировать функцию-обработчика о необходимости срочной остановки
Основные задачи Worker:
- Ожидать появление в канале-очереди task и запустить ее на выполнение
- Остановить работу при закрытии канала-очереди task
- Перехватить panic, обработать ошибку и передать через канал ошибок информацию в pool
- Контролировать команду на остановку со стороны Worker pool
- Контролировать закрытие контекста со стороны Worker pool
- При остановки worker, остановить текущую выполняемую task
- Worker может работать в составе общего sync.WaitGroup, так и изолированно в фоне
Основные задачи Pool:
- Добавлять новые задачи в канал-очередь
- Управлять запуском worker
- Контролировать состояние worker через канал ошибок, перезапускать сбойные worker
- Контролировать команду на остановку со стороны "внешнего мира"
- Контролировать закрытие родительского контекста со стороны "внешнего мира"
- Отработать различные сценарии остановки "Light", "Soft", "Soft + timeout", "Hard"
3. Структура Task
type Task struct {
parentCtx context.Context // родительский контекст, переданный при создании task - используется в функции-обработчике
ctx context.Context // контекст, в рамках которого работает собственно task - используется в функции-обработчике как сигнал для остановки
cancel context.CancelFunc // функция закрытия контекста для task
externalId uint64 // внешний идентификатор запроса, в рамках которого работает task - для целей логирования
doneCh chan<- interface{} // канал сигнала во "внешний мир" о завершении выполнения функции-обработчике
wg *sync.WaitGroup // сигнал во "внешний мир" можно передавать через sync.WaitGroup
stopCh chan interface{} // канал команды на остановку task со стороны "внешнего мира"
localDoneCh chan interface{} // локальный канал task - сигнал о завершении выполнения функции-обработчике для "длинных" task
id uint64 // номер task - для целей логирования
state TaskState // состояние жизненного цикла task
name string // наименование task для логирования и мониторинга
timeout time.Duration // максимальное время выполнения для "длинных" task
timer *time.Timer // таймер остановки по timeout для "длинных" task
requests []interface{} // входные данные запроса - передаются в функцию-обработчик
responses []interface{} // результаты обработки запроса в функции-обработчике
err error // ошибки обработки запроса в функции-обработчике
duration time.Duration // реальная длительность выполнения task
f func(context.Context, context.Context, ...interface{}) (error, []interface{}) // функция-обработчик
mx sync.RWMutex
}
Task управляется следующей статусной моделью.
type TaskState int
const (
TASK_STATE_NEW TaskState = iota // task создан
TASK_STATE_POOL_GET // task получен из pool
TASK_STATE_POOL_PUT // task отправлен в pool
TASK_STATE_READY // task готов к обработкам
TASK_STATE_IN_PROCESS // task выполняется
TASK_STATE_DONE_SUCCESS // task завершился
TASK_STATE_RECOVER_ERR // task остановился из-за паники
TASK_STATE_TERMINATED_STOP_SIGNAL // task остановлен по причине получения сигнала об остановке
TASK_STATE_TERMINATED_CTX_CLOSED // task остановлен по причине закрытия контекста
TASK_STATE_TERMINATED_TIMEOUT // task остановлен по причине превышения timeout
)
Запуск task
Task запускается из goroutine worker
- Заблокируем task на время запуска, чтобы исключить одновременное использование одного указателя task
- Проверим, что запускать можно только task с состоянием TASK_STATE_NEW
- Cтартуем defer функцию для обработки паники task и информирования "внешнего мира" о завершении работы task в отдельный канал doneCh
- "Короткие" task (timeout < 0) не контролируем по timeout. Их нельзя прервать. Функция-обработчик запускается в goroutine worker
- "Длинные" task (timeout >= 0) запускаем в фоне и ожидаем завершения в отдельный локальный канал localDoneCh. Функция-обработчик получает родительский контекст и локальный контекст task. Локальный контекст task нужно контролировать в обработчике для определения необходимости остановки. Ожидаем завершения функции обработчика, наступления timeout или команды на закрытие task
Особенности переиспользования task через sunc.Pool и настройки time.Timer для контроля timeout описаны в разделе "Оптимизация накладных расходов Worker pool"
func (ts *Task) process(workerID uint, workerTimeout time.Duration) {
if ts == nil || ts.f == nil { return }
// Заблокируем task на время запуска, чтобы исключить одновременное использование одного указателя
if ts.mx.TryLock() { // Использование TryLock не рекомендуется, но в данном случае это очень удобно
defer ts.mx.Unlock()
} else {
ts.err = _err.NewTyped(_err.ERR_WORKER_POOL_TASK_ALREADY_LOCKED, ts.externalId, ts.name, ts.state, ts.prevState).PrintfError()
return
}
// Проверим, что запускать можно только готовый task
if ts.state == TASK_STATE_READY {
ts.setStateUnsafe(TASK_STATE_IN_PROCESS)
} else {
ts.err = _err.NewTyped(_err.ERR_WORKER_POOL_TASK_INCORRECT_STATE, ts.externalId, ts.name, ts.state, ts.prevState, "READY").PrintfError()
return
}
// Обрабатываем панику task
defer func() {
if r := recover(); r != nil {
ts.err = _recover.GetRecoverError(r, ts.externalId, ts.name)
ts.setStateUnsafe(TASK_STATE_RECOVER_ERR)
}
}()
// Информируем "внешний мир" о завершении работы task в отдельный канал или через wg
defer func() {
// Возможна ситуация, когда канал закрыт, например, если "внешний мир" нас не дождался по причине своего таймаута, тогда канал уже будет закрыт
if ts.doneCh != nil { ts.doneCh <- struct{}{} }
// Если работали в рамках WaitGroup, то уменьшим счетчик
if ts.wg != nil { ts.wg.Done() }
}()
if ts.timeout < 0 {
// "Короткие" task (timeout < 0) не контролируем по timeout. Их нельзя прервать. Функция-обработчик запускается в goroutine worker
ts.err, ts.responses = ts.f(ts.parentCtx, nil, ts.requests...)
ts.setStateUnsafe(TASK_STATE_DONE_SUCCESS)
return
} else {
// "Длинные" task запускаем в фоне и ожидаем завершения в отдельный локальный канал. Контролируем timeout
var tic = time.Now() // временная метка начала обработки task
go func() {
defer func() {
if r := recover(); r != nil {
ts.err = _recover.GetRecoverError(r, ts.externalId, ts.name)
}
// Отправляем сигнал и закрываем канал, task не контролирует, успешно или нет завершился обработчик
if ts.localDoneCh != nil { ts.localDoneCh <- struct{}{} }
// Если работали в рамках WaitGroup, то уменьшим счетчик
if ts.wg != nil { ts.wg.Done() }
}()
// Обработчик получает родительский контекст и локальный контекст task.
// Локальный контекст task нужно контролировать в обработчике для определения необходимости остановки
ts.err, ts.responses = ts.f(ts.parentCtx, ts.ctx, ts.requests...)
}()
// Определим, нужно ли контролировать timeout, ts.timeout имеет приоритет над workerTimeout
var timeout time.Duration // предельное время работы task
if ts.timeout > 0 {
timeout = ts.timeout
} else if workerTimeout > 0 {
timeout = workerTimeout
}
// Если timeout == 0, то не контролировать timeout
if timeout > 0 {
// Task получает таймер всегда остановленным, сбрасывать канал таймера не требуется, так как он не сработал
ts.timer.Reset(timeout) // Переставим таймер на новое значение
}
// Ожидаем завершения функции обработчика, наступления timeout или команды на закрытие task
select {
case <-ts.localDoneCh:
if !ts.timer.Stop() { // остановим таймер
<-ts.timer.C // Вероятность, что он сработал в промежутке между select из localDoneCh и выполнением ts.timer.Stop() крайне мала
}
ts.duration = time.Now().Sub(tic)
ts.setStateUnsafe(TASK_STATE_DONE_SUCCESS)
return
case _, ok := <-ts.stopCh:
if ok {
// канал был открыт и получили команду на остановку
ts.err = _err.NewTyped(_err.ERR_WORKER_POOL_STOP_SIGNAL, ts.externalId, fmt.Sprintf("[WorkerId='%v', TaskExternalId='%v', TaskName='%v', WorkerTimeout='%v']", workerID, ts.externalId, ts.name, workerTimeout))
ts.setStateUnsafe(TASK_STATE_TERMINATED_STOP_SIGNAL)
} else {
_log.Error("Task - INTERRUPT - stop chanel closed: WorkerId, TaskExternalId, TaskName, WorkerTimeout", workerID, ts.externalId, ts.name, workerTimeout)
}
// Закрываем локальный контекст task - функция обработчика должна корректно отработать это состояние и выполнить компенсационные воздействия
if ts.cancel != nil { ts.cancel() }
close(ts.localDoneCh)
return
case <-ts.timer.C:
ts.err = _err.NewTyped(_err.ERR_WORKER_POOL_TIMEOUT_ERROR, ts.externalId, ts.id, timeout).PrintfError()
ts.setStateUnsafe(TASK_STATE_TERMINATED_TIMEOUT)
// Закрываем локальный контекст task - функция обработчика должна корректно отработать это состояние и выполнить компенсационные воздействия
if ts.cancel != nil { ts.cancel() }
close(ts.localDoneCh)
return
}
}
}
Остановка task
Принудительно остановить "длинные" task можно через специальный канал. Для "коротких" task этот канал не контролируется - остановить их принудительно нельзя.
func (ts *Task) Stop() {
// Останавливать можно только в определенных статусах
if ts.state == TASK_STATE_NEW || ts.state == TASK_STATE_IN_PROCESS || ts.state == TASK_STATE_DONE_SUCCESS {
// Отправляем сигнал и закрываем канал
if ts.stopCh != nil {
ts.stopCh <- true
close(ts.stopCh)
}
}
}
Функция-обработчик task
Пример фукнции-обработчик для расчета факториала n!.
На этом примере в дальнейшем будет тестировать производительность Worker pool для "кротких" task.
func calculateFactorialFn(parentCtx context.Context, ctx context.Context, data ...interface{}) (error, []interface{}) {
var factVal uint64 = 1
var cnt uint64 = 1
// Проверяем количество входных параметров
if len(data) == 1 {
// Проверяем тип входных параметров
if value, ok := data[0].(uint64); ok {
for cnt = 1; cnt <= value; cnt++ {
factVal *= cnt
}
return nil, []interface{}{factVal}
} else {
return _err.NewTyped(_err.ERR_INCORRECT_TYPE_ERROR, _err.ERR_UNDEFINED_ID, "calculateFactorialFn", "0 - uint64", reflect.ValueOf(data[0]).Type().String(), reflect.ValueOf(uint64(1)).Type().String()).PrintfError(), nil
}
}
return _err.NewTyped(_err.ERR_INCORRECT_ARG_NUM_ERROR, _err.ERR_UNDEFINED_ID, data).PrintfError(), nil
}
4. Структура Worker
type Worker struct {
pool *Pool // pool, в состав которого входит worker
parentCtx context.Context // родительский контекст pool, в котором работает worker
externalId uint64 // внешний идентификатор запроса, в рамках которого работает worker - для целей логирования
stopCh chan interface{} // канал команды на остановку worker со стороны "внешнего мира"
id uint // номер worker - для целей логирования
state WorkerState // состояние жизненного цикла worker
errCh chan<- *WorkerError // канал информирования о критичных ошибках worker в pool
timeout time.Duration // максимально время ожидания выполнения task, передается в task при запуске
taskQueueCh <-chan *Task // канал очереди task
taskInProcess *Task // текущая обрабатываемая task
mx sync.RWMutex
}
Worker управляется следующей статусной моделью.
type WorkerState int
const (
WORKER_STATE_NEW WorkerState = iota // worker создан
WORKER_STATE_WORKING // worker обрабатывает задачу
WORKER_STATE_IDLE // worker простаивает
WORKER_STATE_TERMINATING_PARENT_CTX_CLOSED // worker останавливается по причине закрытия родительского контекста
WORKER_STATE_TERMINATING_STOP_SIGNAL // worker останавливается по причине получения сигнала об остановке
WORKER_STATE_TERMINATING_TASK_CH_CLOSED // worker останавливается по причине закрытия канала задач
WORKER_STATE_TERMINATED // worker остановлен
WORKER_STATE_RECOVER_ERR // worker остановился из-за паники
)
Запуск worker
Worker запускается в отдельной goroutine и получает на вход sync.WaitGroup, в составе которого он работает:
- Заблокируем worker на время запуска, чтобы исключить одновременное использование одного указателя
- Проверим, что запускать можно только новый worker или после паники
- Создаем внутренний канал для информирования worker о необходимости срочной остановки со стороны "внешнего мира". Закрывать канал будем в том месте, где отправляется сигнал.
- Обрабатываем панику worker, если работали в рамках WaitGroup, то уменьшим счетчик wg.Done()
- Ждем task из канала-очереди taskQueueCh (пустые задачи игнорируем), сигнала об остановки или закрытия родительского контекста pool
- Если канал-очереди task закрыт - прерываем работу
- При появлении новой task запускаем обработку в своей goroutine.
- Собираются следующие метрики prometheus:
- wp_worker_process_count_vec - количество worker в работе
- wp_task_process_duration_ms_by_name - гистограмма длительности выполнения task в ms с группировкой по task.name
- wp_task_queue_buffer_len_vec - длина канала-очереди task - позволяет анализировать насколько worker pool справляется с нагрузкой
Для команды select нет гарантии, что каналы будут опрошены именно в той последовательности, в которой они написаны. Поэтому в каждой новой итерации сначала проверяем, что worker не остановлен
func (wr *Worker) run(wg *sync.WaitGroup) {
// Заблокируем worker на время запуска, чтобы исключить одновременное использование одного указателя
if wr.mx.TryLock() { // Использование TryLock не рекомендуется, но в данном случае это очень удобно
defer wr.mx.Unlock()
} else {
err := _err.NewTyped(_err.ERR_WORKER_POOL_ALREADY_LOCKED, wr.externalId, wr.id, wr.state).PrintfError()
wr.errCh <- &WorkerError{ // ошибки отправляем в общий канал ошибок pool
err: err,
worker: wr,
}
return
}
// запускать можно только новый worker или после паники
if wr.state == WORKER_STATE_NEW || wr.state == WORKER_STATE_RECOVER_ERR {
wr.setStateUnsafe(WORKER_STATE_IDLE) // worker запущен и простаивает
} else {
err := _err.NewTyped(_err.ERR_WORKER_POOL_RUN_INCORRECT_STATE, wr.externalId, wr.id, wr.state, "NEW', 'RECOVER_ERR").PrintfError()
wr.errCh <- &WorkerError{ // ошибки отправляем в общий канал ошибок pool
err: err,
worker: wr,
}
return
}
// Создаем внутренний канал для информирования worker о необходимости срочной остановки со стороны "внешнего мира"
wr.stopCh = make(chan interface{}, 1)
//defer close(wr.stopCh) !!! закрывать канал будем в том месте, где отправляется сигнал
// Обрабатываем панику worker, если работали в рамках WaitGroup, то уменьшим счетчик
defer func() {
if r := recover(); r != nil {
err := _recover.GetRecoverError(r, wr.externalId)
if err != nil {
wr.setStateUnsafe(WORKER_STATE_RECOVER_ERR)
// ошибки отправляем в общий канал ошибок pool
wr.errCh <- &WorkerError{
err: err,
worker: wr,
}
}
} else {
wr.setStateUnsafe(WORKER_STATE_TERMINATED)
}
// Если работали в рамках WaitGroup, то уменьшим счетчик
if wg != nil { wg.Done() }
}()
// Ждем task из канала-очереди taskQueueCh (пустые задачи игнорируем), сигнала об остановки или закрытия родительского контекста pool
for {
// Для команды select нет гарантии, что каналы будут опрощены именно в той последовательности, в которой они написаны.
// Поэтому в каждой новой итерации сначала проверяем, что worker не остановлен
select {
case _, ok := <-wr.stopCh:
if ok { // канал был открыт и получили команду на остановку
wr.setStateUnsafe(WORKER_STATE_TERMINATING_STOP_SIGNAL)
} else {
// Не корректная ситуация с внутренней логикой - логируем для анализа
_log.Error("Worker - STOP - stop chanel closed: PoolName, WorkerId, WorkerExternalId", wr.pool.name, wr.id, wr.externalId)
}
return
case <-wr.parentCtx.Done():
// закрыт родительский контекст
wr.setStateUnsafe(WORKER_STATE_TERMINATING_PARENT_CTX_CLOSED)
return
default:
}
// Если worker не остановлен, то проверяем канал-очереди задач
select {
case task, ok := <-wr.taskQueueCh:
if ok { // канал очереди задач открыт
if task != nil { // игнорируем пустые задачи
_metrics.IncWPWorkerProcessCountVec(wr.pool.name) // Метрика - количество worker в работе
_metrics.SetWPTaskQueueBufferLenVec(wr.pool.name, float64(len(wr.taskQueueCh))) // Метрика - длина необработанной очереди задач
wr.setStateUnsafe(WORKER_STATE_WORKING)
wr.taskInProcess = task
//_log.Debug("Worker - start to process task: PoolName, WorkerId, WorkerExternalId, TaskName", wr.pool.name, wr.id, wr.externalId, task.name)
task.process(wr.id, wr.timeout)
wr.taskInProcess = nil
wr.setStateUnsafe(WORKER_STATE_IDLE)
_metrics.DecWPWorkerProcessCountVec(wr.pool.name) // Метрика - количество worker в работе
_metrics.IncWPTaskProcessDurationVec(wr.pool.name, task.name, task.duration) // Метрика - время выполнения задачи по имени
}
} else { // Если канал-очереди task закрыт - прерываем работу
wr.setStateUnsafe(WORKER_STATE_TERMINATING_TASK_CH_CLOSED)
return
}
case _, ok := <-wr.stopCh:
if ok { // канал был открыт и получили команду на остановку
wr.setStateUnsafe(WORKER_STATE_TERMINATING_STOP_SIGNAL)
} else {
// Не корректная ситуация с внутренней логикой - логируем для анализа
_log.Error("Worker - STOP - stop chanel closed: PoolName, WorkerId, WorkerExternalId", wr.pool.name, wr.id, wr.externalId)
}
return
case <-wr.parentCtx.Done():
// закрыт родительский контекст
wr.setStateUnsafe(WORKER_STATE_TERMINATING_PARENT_CTX_CLOSED)
return
}
}
}
Остановка worker
Принудительно остановить worker можно через специальный канал stopCh.
- в режиме остановки "Hard" запускаем прерывание текущей "длинной" task
- во всех остальных режимах остановки, текущая task будет доработана до конца
func (wr *Worker) Stop(shutdownMode PoolShutdownMode) {
if wr == nil { return }
// Останавливать можно только в определенных статусах
if wr.state == WORKER_STATE_NEW || wr.state == WORKER_STATE_WORKING || wr.state == WORKER_STATE_IDLE {
// Отправляем сигнал и закрываем канал - если worker ни разу не запускался, то wr.stopCh будет nil
if wr.stopCh != nil {
wr.stopCh <- true
close(wr.stopCh)
}
// В режиме остановки "Hard" запускаем прерывание текущей task
if shutdownMode == POOL_SHUTDOWN_HARD {
if wr.taskInProcess != nil {
wr.taskInProcess.Stop()
}
}
}
}
5. Структура Pool
type Pool struct {
cfg *Config // конфиг pool
parentCtx context.Context // родительский контекст, в котором создали pool
ctx context.Context // контекст, в котором работает pool
cancel context.CancelFunc // функция закрытия контекста для pool
externalId uint64 // внешний идентификатор, в рамках которого работает pool - для целей логирования
name string // имя pool для сбора метрик и логирования
state PoolState // состояние жизненного цикла pool
stopCh chan interface{} // канал команды на остановку pool со стороны "внешнего мира"
isBackground bool // pool запущен в background режиме
workers map[int]*Worker // набор worker
workerConcurrency int // уровень параллелизма - если 0, то количество ядер х 2
workerTimeout time.Duration // таймаут выполнения задачи одним worker
workerErrCh chan *WorkerError // канал ошибок workers, размер определяется количеством worker
taskQueueCh chan *Task // канал очереди задач, ожидающих выполнения
taskQueueSize int // размер очереди задач - если 0, то количество ядер х 1000
mx sync.RWMutex
}
Pool управляется следующей статусной моделью.
type PoolState int
const (
POOL_STATE_NEW PoolState = iota // pool создан, еще ни разу не запускался
POOL_STATE_ONLINE_RUNNING // pool запущен в режиме online, добавление новых задач запрещено
POOL_STATE_ONLINE_DONE // pool запущенный в режиме online, завершил обработку всех задач
POOL_STATE_INCOMPLETE_DONE // pool запущенный в режиме online, завершил обработку НЕ всех задач
POOL_STATE_RECOVER_ERR // pool остановлен по панике, дальнейшие действия не возможны
POOL_STATE_BG_RUNNING // pool запущен в режиме background, добавление новых задач разрешено
POOL_STATE_SHUTTING_DOWN // pool находится в режиме остановки, добавление новых задач запрещено
POOL_STATE_TERMINATE_TIMEOUT // pool превышено время ожидания остановки
POOL_STATE_SHUTDOWN // pool успешно остановлен
)
Запуск Pool
Pool может запускаться в двух режимах
- online - в этом режиме pool принимает на вход полный набор task для выполнения, по завершению обработки всех task он удаляется. Этот режим запуска в статье не описывается - его можно посмотреть в репозитории проекта.
- background - в этом режиме pool запускается в фоне, стартует необходимое количество обработчиков и ожидает поступления задач в очередь
Background Pool запускается в отдельной goroutine:
- Блокируем pool на время инициализации, иначе task могут начать поступать раньше, чем он стартует
- Проверяется, что уже запущенный pool запустить повторно нельзя
- Инициализация всех внутренних структур
- Стартуем в фоне workers, передаем им канал ошибок и канал-очередь task
- Разблокируем pool, он готов к работе - можно принимать новый task в канал-очередь
- Ожидаем ошибки от worker, закрытия родительского контекста или остановки pool
func (p *Pool) RunBG(externalId uint64, shutdownTimeout time.Duration) (err error) {
if p == nil {
return _err.NewTyped(_err.ERR_INCORRECT_CALL_ERROR, externalId, "Nil Pool pointer").PrintfError()
}
// Блокируем pool на время инициализации, иначе task могут начать поступать раньше, чем он стартует
p.mx.Lock()
// Уже запущенный pool запустить повторно нельзя
if p.state == POOL_STATE_NEW {
p.setStateUnsafe(POOL_STATE_BG_RUNNING)
p.isBackground = true
p.externalId = externalId
} else {
err = _err.NewTyped(_err.ERR_WORKER_POOL_RUN_INCORRECT_STATE, p.externalId, p.name, p.state, "NEW").PrintfError()
p.mx.Unlock()
return err
}
// Инициализация всех внутренних структур
p.ctx, p.cancel = context.WithCancel(context.Background()) // Работаем в изолированном от родительского контексте
p.workers = make(map[int]*Worker, p.workerConcurrency) // Набор worker
p.workerErrCh = make(chan *WorkerError, p.workerConcurrency) // достаточно по одной ошибке на worker
p.taskQueueCh = make(chan *Task, p.taskQueueSize) // Канал-очередь task
p.stopCh = make(chan interface{}, 1) // Внутренний канал для информирования pool о необходимости срочной остановки со стороны "внешнего мира"
//defer close(p.stopCh) закрывать канал будем в том месте, где отправляется сигнал
// Функция восстановления после глобальной паники и закрытия контекста
defer func() {
if r := recover(); r != nil {
err = _recover.GetRecoverError(r, p.externalId)
p.mx.Lock()
defer p.mx.Unlock()
p.setStateUnsafe(POOL_STATE_RECOVER_ERR)
_ = p.shutdownUnsafe(POOL_SHUTDOWN_HARD, shutdownTimeout) // экстренная остановка, ошибку игнорируем
}
if p.cancel != nil { p.cancel() }
}()
// Стартуем в фоне workers, передаем им канал ошибок и канал-очередь task
for workerId := 1; workerId <= p.workerConcurrency; workerId++ {
worker := newWorker(p.ctx, p, p.taskQueueCh, uint(workerId), p.externalId, p.workerErrCh, p.workerTimeout)
p.workers[workerId] = worker
go worker.run(nil) // Запускаем в фоне без WaitGroup
}
// Pool готов к работе - можно принимать новый task в канал-очередь
p.mx.Unlock()
// Ожидаем ошибки от worker, закрытия родительского контекста или остановки pool
for {
select {
case workerErr, ok := <-p.workerErrCh:
if ok { // канал открыт - нормальная работа pool
_ = _err.WithCauseTyped(_err.ERR_WORKER_POOL_WORKER_ERROR, p.externalId, workerErr.err, p.name, workerErr.worker.id, workerErr.err.Error()).PrintfError()
if workerErr.worker != nil {
go workerErr.worker.run(nil) // стартуем worker заново
}
} else { // канал закрыт - нормальная ситуация при остановке pool
return nil
}
case <-p.stopCh:
// Нормальный вариант остановки
return nil
case <-p.parentCtx.Done():
// Закрылся родительский контекст - останавливаем все worker
p.mx.Lock()
// ошибки будут переданы через именованную переменную возврата
err = p.shutdownUnsafe(POOL_SHUTDOWN_HARD, shutdownTimeout)
p.mx.Unlock()
return err
}
}
}
Добавление новых task в очередь
- Блокируем pool для проверки статуса и чтобы задержать отправку task до полной инициации pool
- Обработать ошибки закрытия канала-очереди task
- Очередь имеет ограниченный размер - возможно ожидание, пока не появится свободное место.
Канал-очередь задач мониторится двумя метриками:
- wp_add_task_wait_count_vec - количество задач, ожидающих попадания в очередь
- wp_task_queue_buffer_len_vec - текущая длина канала-очереди task - показывает заполненность канала
Зачем иметь размер канала-очереди больше чем количество обработчиков?
Это полезно если используется асинхронный режим работы с внешними потребителями Worker pool. Первая операция - добавления task должна быть максимально быстрой - для этого в очереди должно быть свободное место. Рост метрики wp_add_task_wait_count_vec позволяет оценить узкое место и, нарпимер, стартовать новый Pod (при использовании Kubernetes операторов).
func (p *Pool) AddTask(task *Task) (err error) {
if p == nil { return _err.NewTyped(_err.ERR_INCORRECT_CALL_ERROR, _err.ERR_UNDEFINED_ID, "Nil Pool pointer").PrintfError() }
if task == nil { return nil } // Пустую задачу игнорируем
// Блокируем pool для проверки статуса и чтобы задержать отправку task до полной инициации pool
p.mx.RLock()
// Добавление task запрещено
if p.state != POOL_STATE_BG_RUNNING {
err = _err.NewTyped(_err.ERR_WORKER_POOL_ADD_TASK_INCORRECT_STATE, p.externalId, p.state, "NEW, RUNNING_BG, PAUSED_BG").PrintfError()
p.mx.RUnlock()
return err
}
p.mx.RUnlock()
// Обработать ошибки закрытия канала-очереди task
defer func() {
if r := recover(); r != nil {
err = _recover.GetRecoverError(r, p.externalId)
}
}()
_metrics.IncWPAddTaskWaitCountVec(p.name) // Счетчик ожиданий отправки в очередь - увеличить
if task.wg != nil { task.wg.Add(1) } // Если работаем в рамках WaitGroup
p.taskQueueCh <- task // Очередь имеет ограниченный размер - возможно ожидание, пока не появится свободное место
_metrics.DecWPAddTaskWaitCountVec(p.name) // Счетчик ожиданий отправки в очередь - отправили - уменьшить
return nil
}
Остановка pool
- Закрываем канал задач для Background pool, для Online он уже закрыт
- В режиме остановки "hard" и "soft", вычитываем task из очереди и останавливаем их
- Запускаем остановку worker и ожидаем успешной остановки или shutdownTimeout, если shutdownTimeout == 0, то бесконечное ожидание
- Проверим ошибки от worker, которые накопились в канале workerErrCh
Суффиксом Unsafe помечены функции, которые небезопасны для использования вне блокировки sync.RWMutex. Так же в них запрещены блокировка sync.RWMutex.
func (p *Pool) shutdownUnsafe(shutdownMode PoolShutdownMode, shutdownTimeout time.Duration) (err error) {
// исключить повторную остановку
if p.state != POOL_STATE_SHUTDOWN && p.state != POOL_STATE_SHUTTING_DOWN {
//_log.Debug("Pool - SHUTTING DOWN : ExternalId, PoolName, ActiveTaskCount, State", p.externalId, p.name, len(p.taskQueueCh), p.state)
// Функция восстановления после паники
defer func() {
if r := recover(); r != nil {
err = _recover.GetRecoverError(r, p.externalId)
}
p.setStateUnsafe(POOL_STATE_SHUTDOWN) // Остановка закончена
}()
p.setStateUnsafe(POOL_STATE_SHUTTING_DOWN) // Начало остановки - в этом статусе запрещено принимать новые task
// Закрываем канал задач для Background pool, для Online он уже закрыт
if p.isBackground { close(p.taskQueueCh) }
// В режиме остановки "hard" и "soft", вычитываем task из очереди и останавливаем их
if shutdownMode == POOL_SHUTDOWN_HARD || shutdownMode == POOL_SHUTDOWN_SOFT {
for task := range p.taskQueueCh {
if task != nil { task.Stop() }
}
}
// Запускаем остановку worker и ожидаем успешной остановки или shutdownTimeout, если shutdownTimeout == 0, то бесконечное ожидание
p.stopWorkersUnsafe(shutdownMode, shutdownTimeout)
close(p.workerErrCh) // Закрываем канал ошибок worker
// Проверим ошибки от worker, которые накопились в канале
if len(p.workerErrCh) != 0 {
// Накопленные ошибки worker залогируем, последнюю передадим на верх
for workerErr := range p.workerErrCh {
//_log.Debug("Pool online - DONE - Worker error: error", workerErr.err.Error())
err = _err.WithCauseTyped(_err.ERR_WORKER_POOL_WORKER_ERROR, p.externalId, workerErr.err, p.name, workerErr.worker.id, workerErr.err.Error()).PrintfError()
}
}
}
return err
}
6. Оптимизация Worker pool
Оптимизация расхода памяти на создание task
Основные расходы памяти приходятся на создание новой структуры task при добавлении задачи в очередь. После выполнения task структура будет собрана GC.
Для решения этой проблемы отлично подходит sync.Pool. Вместо, того, чтобы "выбрасывать" task после отработки, будет складывать их в sync.Pool, а при добавлении новой задачи в очередь, брать их из sync.Pool.
// Подготовим список задач для запуска
for i, value := range *wpFactorialReqResp.NumArray {
task := _wp.NewTask(ctx, "", nil, uint64(i), requestID, -1*time.Second, calculateEmptyFn, value)
tasks = append(tasks, task)
}
// в конце обработки отправить task в кэш для повторного использования
defer func() {
for _, task := range tasks {
task.Delete()
}
}()
Оптимизация работы с time.Timer
Для того чтобы контролировать время выполнения функции-обработчика task, используется time.Timer.
В простейшем случае, можно использовать такую конструкцию с time.After(ts.timeout) в task.
select {
case <-ts.localDoneCh:
...
case _, ok := <-ts.stopCh:
...
case <-time.After(ts.timeout):
ts.err = _err.NewTyped(_err.ERR_WORKER_POOL_TIMEOUT_ERROR, ts.externalId, ts.timeout).PrintfError()
ts.setState(TASK_STATE_TERMINATED_TIMEOUT)
return
}
Только есть одно "но", time.After создает новый канал для контроля времени и этот канал не будет удален CG, пока таймер не сработает. В результате получите большой расход памяти и потери по времени в 2-3 раза на интенсивных операциях с task.
Вместо time.After, в приведенном шаблоне используется явное управление созданием, остановкой и сбросом time.Timer.
- time.Timer создается один раз при создании новой task и устанавливается в максимальное значение (константа workerpoolю.POOL_MAX_TIMEOUT)
- после создания time.Timer сразу останавливается timer.Stop(). При запуске task.process получает на вход всегда остановленный time.Timer
- при выполнении task.process устанавливает правильный timeout, который нужно контролировать, и запускает time.Timer. Если timeout == 0, то time.Timer на запускается
- при успешном выполнении функции-обработчика, task сразу останавливает time.Timer. Вероятность, что Timer сработал в промежутке между select из localDoneCh и выполнением ts.timer.Stop() крайне мала, но нужно подстраховаться и очистить канал.
if !ts.timer.Stop() {
<-ts.timer.C // Вероятность, что он сработал в промежутке между select из localDoneCh и выполнением ts.timer.Stop() крайне мала
}
Такой подход позволяет постоянно использовать один и тот же time.Timer.
Так выглядит использование памяти оптимизированного workerp pool под нагрузкой - всего 16 Мбайт
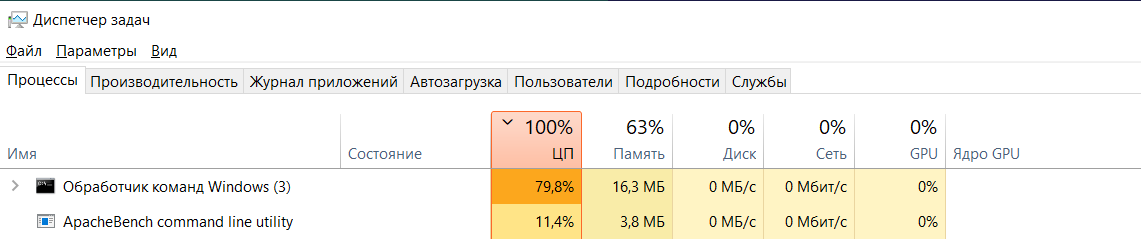
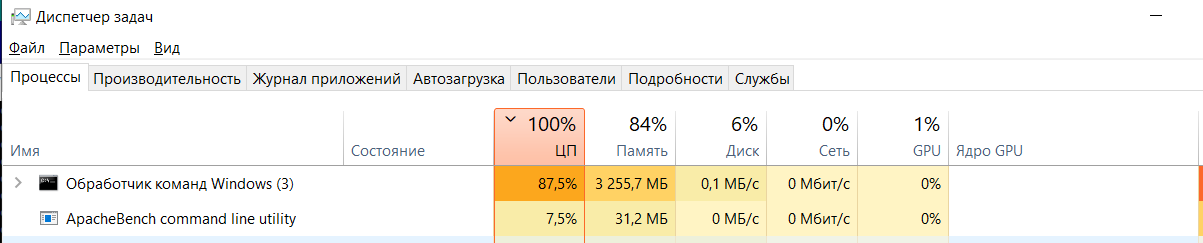
А так выглядит вариант с неправильным использованием time.After под нагрузкой - уже 3255 Мбайт
Реализация TaskPool
Реализация TaskPool
- При создании новой task создаются все необходимые каналы, контекст и таймер
- При получении task из sync.Pool дополнительных действий не требуется
- При помещении task в sync.Pool проверяется ее статус.
- Если task успешно выполнился, то каналы остались открытыми, таймер не сработал и контекст не закрыт. Такой task подходит для повторного использования - его можно поместить в sync.Pool
- В противном случае task не помещается в sync.Pool и позже может быть собран CG
// TaskPool represent pooling of Task
type TaskPool struct {
pool sync.Pool
}
// Represent a pool statistics for benchmarking
var (
countGet uint64 // количество запросов кэша
countPut uint64 // количество возвратов в кэша
countNew uint64 // количество создания нового объекта
)
// newTaskPool create new TaskPool
func newTaskPool() *TaskPool {
p := &TaskPool{
pool: sync.Pool{
New: func() interface{} {
atomic.AddUint64(&countNew, 1)
task := new(Task)
task.stopCh = make(chan interface{}, 1) // канал закрывается только при получении команды на остановку task
task.localDoneCh = make(chan interface{}, 1) // канал закрывается при timeout и при получении команды на остановку task
task.timer = time.NewTimer(POOL_MAX_TIMEOUT) // новый таймер - начально максимальное время ожидания
task.timer.Stop() // остановим таймер, сбрасывать канал не требуется, так как он не сработал
task.ctx, task.cancel = context.WithCancel(context.Background()) // создаем локальный контекст с отменой
task.setStateUnsafe(TASK_STATE_NEW) // установим состояние task
return task
},
},
}
return p
}
// getTask allocates a new Task
func (p *TaskPool) getTask() *Task {
atomic.AddUint64(&countGet, 1)
task := p.pool.Get().(*Task)
if task.state != TASK_STATE_NEW {
task.setStateUnsafe(TASK_STATE_POOL_GET) // установим состояние task
}
return task
}
// putTask return Task to pool
func (p *TaskPool) putTask(task *Task) {
// Если task не был успешно завершен, то в нем могли быть закрыты каналы или сработал таймер - такие не подходят для повторного использования
if task.state == TASK_STATE_NEW || task.state == TASK_STATE_DONE_SUCCESS || task.state == TASK_STATE_POOL_GET {
atomic.AddUint64(&countPut, 1)
task.requests = nil // обнулить указатель, чтобы освободить для сбора мусора
task.responses = nil // обнулить указатель, чтобы освободить для сбора мусора
task.setState(TASK_STATE_POOL_PUT) // установим состояние task с ожиданием разблокировки
p.pool.Put(task) // отправить в pool
}
}
// глобальный TaskPool
var gTaskPool = newTaskPool()
// PrintTaskPoolStats print statistics about task pool
func (p *Pool) PrintTaskPoolStats() {
if p != nil {
_log.Info("Usage task pool: countGet, countPut, countNew", countGet, countPut, countNew)
} else {
_ = _err.NewTyped(_err.ERR_INCORRECT_CALL_ERROR, _err.ERR_UNDEFINED_ID, "p != nil").PrintfError()
}
}
7. Нагрузочное тестирование Worker pool
Сценарий тестирования
Для тестирования выбрал крайне нагруженный пример "коротких" task - будем считать сумму факториалов в группе task.
Каждый task из группы выполняется в отдельно и по завершению всей группы результаты суммируются.
Фукнция-обработчик для расчета факториала n!.
func calculateFactorialFn(parentCtx context.Context, ctx context.Context, data ...interface{}) (error, []interface{}) {
var factVal uint64 = 1
var cnt uint64 = 1
// Проверяем количество входных параметров
if len(data) == 1 {
// Проверяем тип входных параметров
if value, ok := data[0].(uint64); ok {
for cnt = 1; cnt <= value; cnt++ {
factVal *= cnt
}
return nil, []interface{}{factVal}
} else {
return _err.NewTyped(_err.ERR_INCORRECT_TYPE_ERROR, _err.ERR_UNDEFINED_ID, "calculateFactorialFn", "0 - uint64", reflect.ValueOf(data[0]).Type().String(), reflect.ValueOf(uint64(1)).Type().String()).PrintfError(), nil
}
}
return _err.NewTyped(_err.ERR_INCORRECT_ARG_NUM_ERROR, _err.ERR_UNDEFINED_ID, data).PrintfError(), nil
}
Фукнция-обработчик для формирования группы task и суммирования результатов.
// calculateFactorial функция запуска расчета Factorial
func calculateFactorial(ctx context.Context, wpService *_wpservice.Service, requestID uint64, wpFactorialReqResp *WpFactorialReqResp, wpTipe string, tasks []*_wp.Task) (err error) {
// Подготовим список задач для запуска
for i, value := range *wpFactorialReqResp.NumArray {
task := _wp.NewTask(ctx, "CalculateFactorial", nil, uint64(i), requestID, -1*time.Second, calculateFactorialFn, value)
tasks = append(tasks, task)
}
// в конце обработки отправить task в кэш для повторного использования
defer func() {
for _, task := range tasks {
task.Delete()
}
}()
// Запускаем обработку в общий background pool
err = wpService.RunTasksGroupWG(requestID, tasks, "Calculate - background")
// Анализ результатов
if err == nil {
// Суммируем все результаты
for _, task := range tasks {
if task.GetError() == nil {
result := task.GetResponses()[0] // ожидаем только один ответ
// Приведем к нужному типу
if factorial, ok := result.(uint64); ok {
wpFactorialReqResp.SumFactorial += factorial
} else {
return _err.NewTyped(_err.ERR_INCORRECT_TYPE_ERROR, _err.ERR_UNDEFINED_ID, "WpHandlerFactorial", "0 - uint", reflect.ValueOf(factorial).Type().String(), reflect.ValueOf(uint64(1)).Type().String()).PrintfError()
}
} else {
_log.Error("Task error", requestID, task.GetError())
return task.GetError()
}
}
} else {
_log.Error("RunTasksGroupWG error", requestID, err)
}
return err
}
Benchmark для тестирования
Содержит наборы task в диапазоне от 1 до 4096. Запуск через командную строку. Чтобы получить репрезентативную выборку, запускаем 5 тестов
go.exe test -benchmem -run=^$ -bench ^BenchmarkCalculateFactorial$ github.com/romapres2010/goapp/pkg/app/httphandler -count 5 -v
- Создаем Worker pool service
- Запускаем Worker pool service в фоне и делаем минимальную задержку для инициации pool
- Далее в цикле запускаем нужный тестовый набор от 1 до 4096 task
- Останавливаем обработчик Worker pool service
func BenchmarkCalculateFactorial(b *testing.B) {
// конфигурационные параметры для Worker pool service, все timeout выставлены в заведомо большие значения, чтобы не срабатывали.
var wpServiceCfg = &_wpservice.Config{
TotalTimeout: 100000 * time.Millisecond,
ShutdownTimeout: 30 * time.Second,
WPCfg: _wp.Config{
TaskQueueSize: 0,
TaskTimeout: 20000 * time.Millisecond,
WorkerConcurrency: 4,
WorkerTimeout: 30000 * time.Millisecond,
},
}
var wpService *_wpservice.Service // сервис worker pool
var wpServiceErrCh = make(chan error, wpServiceCfg.WPCfg.WorkerConcurrency) // канал ошибок для сервиса worker pool
var err error
var parentCtx = context.Background()
// Создаем Worker pool service
if wpService, err = _wpservice.New(parentCtx, "WorkerPool - background", wpServiceErrCh, wpServiceCfg); err != nil {
return
}
// Запускаем Worker pool service в фоне и делаем минимальную задержку для инициации pool
go func() { wpServiceErrCh <- wpService.Run() }()
time.Sleep(1 * time.Microsecond)
b.ResetTimer()
for i := 0; i < b.N; i++ {
wpFactorialReqResp := &WpFactorialReqResp{
NumArray: NumArray1024,
}
_ = calculateFactorial(parentCtx, wpService, 0, wpFactorialReqResp, "bg", tasks)
}
// Останавливаем обработчик Worker pool service
if err = wpService.Shutdown(false, wpServiceCfg.ShutdownTimeout); err != nil {
_log.ErrorAsInfo(err) // дополнительно логируем результат остановки
}
}
Результаты тестирования для 1 task
- Тестируем неоптимизированный вариант worker pool. Без использования sync.Pool и с time.After
2023-03-05 20:51:23.730300 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['993524', '0', '993524']
2023-03-05 20:51:23.746665 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['993624', '0', '993624']
2023-03-05 20:51:23.881707 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1003624', '0', '1003624']
2023-03-05 20:51:24.686886 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1095245', '0', '1095245']
2023-03-05 20:51:25.880455 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1233606', '0', '1233606']
BenchmarkCalculateFactorial-4 138361 8553 ns/op 1209 B/op 21 allocs/op
PASS
ok github.com/romapres2010/goapp/pkg/app/httphandler 11.171s
- Тестируем оптимизированный вариант worker pool. Включен sync.Pool и с time.timer
2023-03-05 20:59:06.661061 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1026975', '1026975', '26']
2023-03-05 20:59:06.678355 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1027075', '1027075', '27']
2023-03-05 20:59:06.863869 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1036025', '1036025', '28']
2023-03-05 20:59:07.613347 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1130840', '1130840', '30']
2023-03-05 20:59:08.893377 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['1284189', '1284189', '32']
BenchmarkCalculateFactorial-4 153349 8331 ns/op 464 B/op 11 allocs/op
PASS
Результаты тестирования для 100 task
- Тестируем неоптимизированный вариант worker pool. Без использования sync.Pool и с time.After
2023-03-05 20:54:31.642079 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['3431200', '0', '3431200']
2023-03-05 20:54:31.706946 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['3440400', '0', '3440400']
2023-03-05 20:54:32.041946 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['3618100', '0', '3618100']
2023-03-05 20:54:33.230567 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['4277500', '0', '4277500']
BenchmarkCalculateFactorial-4 6594 179944 ns/op 80624 B/op 1308 allocs/op
PASS
ok github.com/romapres2010/goapp/pkg/app/httphandler 8.237s
- Тестируем оптимизированный вариант worker pool. Включен sync.Pool и с time.timer
2023-03-05 20:58:13.493850 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['5921000', '5921000', '138']
2023-03-05 20:58:13.513097 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['5931000', '5931000', '139']
2023-03-05 20:58:14.268227 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['6591200', '6591200', '144']
2023-03-05 20:58:15.388267 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['7658300', '7658300', '149']
BenchmarkCalculateFactorial-4 10671 103819 ns/op 6246 B/op 308 allocs/op
PASS
ok github.com/romapres2010/goapp/pkg/app/httphandler 8.513s
Результаты тестирования для 1024 task
- Тестируем неоптимизированный вариант worker pool. Без использования sync.Pool и с time.After
2023-03-05 20:55:16.861903 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['5306368', '0', '5306368']
2023-03-05 20:55:17.041430 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['5374976', '0', '5374976']
2023-03-05 20:55:17.884380 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['5868544', '0', '5868544']
2023-03-05 20:55:19.021540 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['6581248', '0', '6581248']
BenchmarkCalculateFactorial-4 696 1623650 ns/op 819853 B/op 13321 allocs/op
PASS
ok github.com/romapres2010/goapp/pkg/app/httphandler 11.370s
- Тестируем оптимизированный вариант worker pool. Включен sync.Pool и с time.timer
2023-03-05 20:57:24.753063 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['10350592', '10350592', '2080']
2023-03-05 20:57:24.863404 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['10422272', '10422272', '2082']
2023-03-05 20:57:25.523164 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['11227136', '11227136', '2085']
2023-03-05 20:57:26.738321 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['12699648', '12699648', '2089']
BenchmarkCalculateFactorial-4 1438 837543 ns/op 61221 B/op 3082 allocs/op
PASS
ok github.com/romapres2010/goapp/pkg/app/httphandler 10.800s
Сравнение результатов
Сравним результаты в пересчете на одну task
- 1 task
- неоптимизированный - 8553 ns/op 1209 B/op 21 allocs/op
- оптимизированный - 8331 ns/op 464 B/op 11 allocs/op
- 100 task
- неоптимизированный - 1799 ns/op 806 B/op 13 allocs/op
- оптимизированный - 1038 ns/op 62 B/op 3 allocs/op
- 1024 task
- неоптимизированный - 1620 ns/op 810 B/op 13 allocs/op
- оптимизированный - 830 ns/op 61 B/op 3 allocs/op
При большом количестве task, минимум двухкратный выигрыш по cpu и более чем десятикратный по памяти.
Оценить эффективность работы TaskPool можно по количеству запрошенных и созданных новых объектах task.
- из 12 699 648 запросов было создано новых 2089
- из 12 699 648 запросов все были возвращены в sync.Pool, сбойных task не было
Usage task pool: countGet, countPut, countNew['12699648', '12699648', '2089']
Контрольный выстрел
Сравним, сколько занимает расчет суммы факториалов 50! без использования worker pool в один поток для 1024 значений
2023-03-05 21:05:40.898732 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['0', '0', '0']
2023-03-05 21:05:40.914259 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['0', '0', '0']
2023-03-05 21:05:41.298531 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['0', '0', '0']
2023-03-05 21:05:42.498569 info workerpool/taskpool.go:68 (*Pool).PrintTaskPoolStats() - Usage task pool: countGet, countPut, countNew['0', '0', '0']
BenchmarkCalculateFactorial-4 26288 45514 ns/op 0 B/op 0 allocs/op
PASS
ok github.com/romapres2010/goapp/pkg/app/httphandler 8.675s
Оптимизированный worker pool (на 2 физических ярах) отстает в 20 раз от прямого расчета суммы факториалов в один поток. На 6-8 ядрах можно сократить разрыв до 8-10 раз, дальше рост количества ядер не сильно поможет.
Используйте worker pool разумно - не везде он нужен
Для task, которые должны выполняться быстрее 200 ns/op представленный Worker pool использовать не эффективно.
8. Профилирование Worker pool
Обработчик для профилирования
Для профилирования подготовим упрощенный обработчик, который ни чего не делает в task
// calculateEmpty функция оценки накладных расходов worker pool
func calculateEmpty(ctx context.Context, wpService *_wpservice.Service, requestID uint64, wpFactorialReqResp *WpFactorialReqResp, wpTipe string, tasks []*_wp.Task) (err error) {
// Подготовим список задач для запуска
for i, value := range *wpFactorialReqResp.NumArray {
task := _wp.NewTask(ctx, "", nil, uint64(i), requestID, -1*time.Second, calculateEmptyFn, value)
tasks = append(tasks, task)
}
// в конце обработки отправить task в кэш для повторного использования
defer func() {
for _, task := range tasks {
task.Delete()
}
}()
// Запускаем обработку в общий background pool
err = wpService.RunTasksGroupWG(requestID, tasks, "")
return err
}
// calculateEmpty функция запуска оценки накладных расходов worker pool
func calculateEmptyFn(parentCtx context.Context, ctx context.Context, data ...interface{}) (error, []interface{}) {
return nil, nil // для оценки накладных расходов на Worker pool
}
Результат профилирования
Результат профилирования для "длинных" task
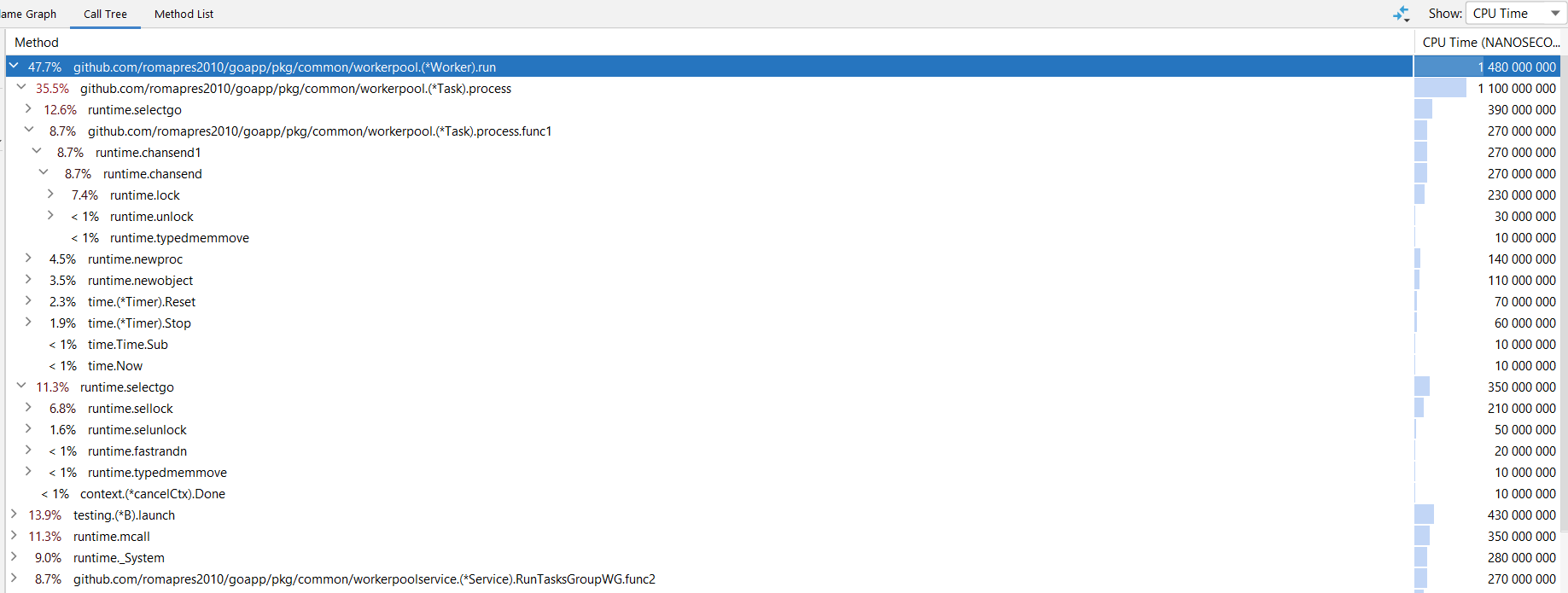
- Memory
- workerpool.(*Worker).run - память не выделялась
- workerpool.(*Task).process - выделено память для 2042881 объектов, всего 33030648 байт - 16 байт на один task
- CPU
- workerpool.(*Worker).run - 1480 ns из которых,
- чтение каналов очереди задач и остановки - 350 ns
- workerpool.(*Task).process - 1100 ns из которых,
- 390 ns - ожидание информации в канал о завершении функции-обработчика и таймера,
- 140 ns - запуск функции-обработчика в отдельной goroutine
- 270 ns - информирование "внешнего мира" о завершении task в канал ответа
- 130 ns - перезапуск и остановка таймера,
- workerpool.(*Worker).run - 1480 ns из которых,
Результат профилирования для "коротких" task
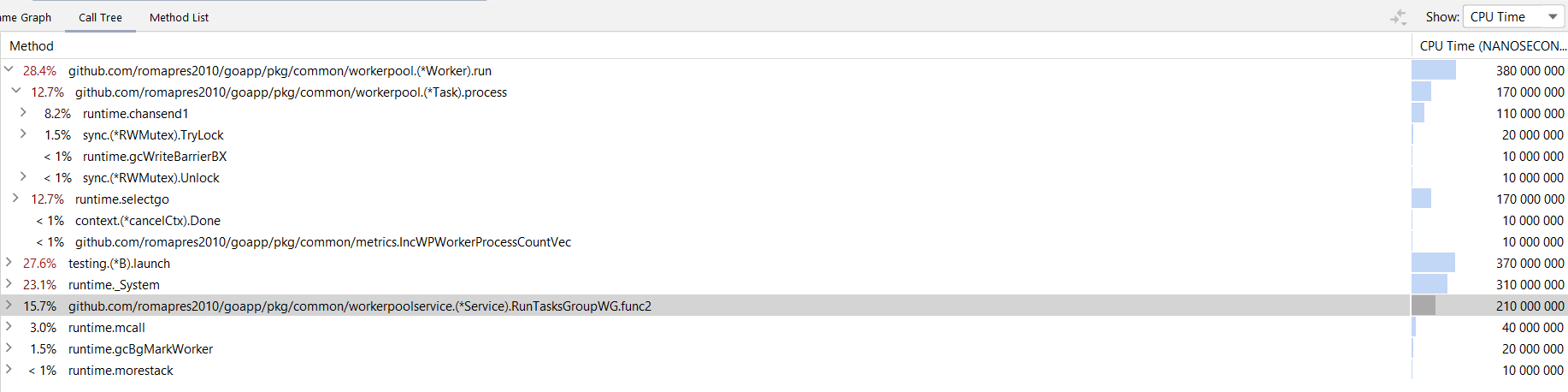
- Memory
- workerpool.(*Worker).run - память не выделялась
- workerpool.(*Task).process - память не выделялась
- CPU
- workerpool.(*Worker).run - 380 ns из которых,
- чтение каналов очереди задач и остановки - 170 ns
- workerpool.(*Task).process - 170 ns из которых,
- 110 ns - информирование "внешнего мира" о завершении task в канал ответа
- workerpool.(*Worker).run - 380 ns из которых,
 Documentation
¶
Documentation
¶
Index ¶
- Constants
- type Config
- type Pool
- func (p *Pool) AddTask(task *Task) (err error)
- func (p *Pool) GetState() PoolState
- func (p *Pool) PrintTaskPoolStats()
- func (p *Pool) RunBG(externalId uint64, shutdownTimeout time.Duration) (err error)
- func (p *Pool) RunOnline(externalId uint64, tasks []*Task, shutdownTimeout time.Duration) (err error)
- func (p *Pool) Stop(shutdownMode PoolShutdownMode, shutdownTimeout time.Duration) (err error)
- type PoolShutdownMode
- type PoolState
- type Task
- func (ts *Task) DeleteUnsafe()
- func (ts *Task) GetError() error
- func (ts *Task) GetExternalId() uint64
- func (ts *Task) GetRequests() []interface{}
- func (ts *Task) GetResponses() []interface{}
- func (ts *Task) SetDoneChUnsafe(doneCh chan<- interface{})
- func (ts *Task) SetError(err error)
- func (ts *Task) SetWgUnsafe(wg *sync.WaitGroup)
- func (ts *Task) Stop()
- type TaskPool
- type TaskState
- type Worker
- type WorkerError
- type WorkerState
Constants ¶
const POOL_MAX_TIMEOUT = time.Hour * 24 * 365
Variables ¶
This section is empty.
Functions ¶
This section is empty.
Types ¶
type Config ¶
type Config struct {
TaskQueueSize int `yaml:"task_queue_size" json:"task_queue_size"` // размер очереди задач - если 0, то количество ядер х 1000
TaskTimeout time.Duration `yaml:"task_timeout" json:"task_timeout"` // максимальное время обработки одного расчета
WorkerConcurrency int `yaml:"worker_concurrency" json:"worker_concurrency"` // уровень параллелизма - если 0, то количество ядер х 2
WorkerTimeout time.Duration `yaml:"worker_timeout" json:"worker_timeout"` // максимальное время обработки задачи worker
}
Config - конфигурационные настройки pool
type Pool ¶
type Pool struct {
// contains filtered or unexported fields
}
Pool - управление набором worker и выполнения task
func (*Pool) PrintTaskPoolStats ¶
func (p *Pool) PrintTaskPoolStats()
PrintTaskPoolStats print statistics about task pool
type PoolShutdownMode ¶
type PoolShutdownMode int
PoolShutdownMode - режим остановки pool
const ( POOL_SHUTDOWN_LIGHT PoolShutdownMode = iota // все начатые к обработке и все взятые в очередь задачи должны быть завершены, новые задачи не принимаются POOL_SHUTDOWN_SOFT // только начатые к обработке задачи должны быть завершены, новые задачи не принимаются, оставшиеся в очереди задачи останавливаются с ошибкой POOL_SHUTDOWN_HARD // экстренно прерывается обработка всех задач, как начатых, так и находящихся в очереди )
type PoolState ¶
type PoolState int
PoolState - статусы жизненного цикла pool
const ( POOL_STATE_NEW PoolState = iota // pool создан, еще ни разу не запускался POOL_STATE_ONLINE_RUNNING // pool запущен в режиме online, добавление новых задач запрещено POOL_STATE_ONLINE_DONE // pool запущенный в режиме online, завершил обработку всех задач POOL_STATE_INCOMPLETE_DONE // pool запущенный в режиме online, завершил обработку НЕ всех задач POOL_STATE_RECOVER_ERR // pool остановлен по панике, дальнейшие действия не возможны POOL_STATE_BG_RUNNING // pool запущен в режиме background, добавление новых задач разрешено POOL_STATE_SHUTTING_DOWN // pool находится в режиме остановки, добавление новых задач запрещено POOL_STATE_TERMINATE_TIMEOUT // pool превышено время ожидания остановки POOL_STATE_SHUTDOWN // pool успешно остановлен )
type Task ¶
type Task struct {
// contains filtered or unexported fields
}
Task - содержимое задачи и результаты выполнения
func (*Task) GetExternalId ¶
GetExternalId - считать externalId из task
func (*Task) GetRequests ¶
func (ts *Task) GetRequests() []interface{}
GetRequests - считать результаты задания task
func (*Task) GetResponses ¶
func (ts *Task) GetResponses() []interface{}
GetResponses - считать результаты из task
func (*Task) SetDoneChUnsafe ¶
func (ts *Task) SetDoneChUnsafe(doneCh chan<- interface{})
SetDoneChUnsafe - внешний мир может установить канал для уведомления о завершении
func (*Task) SetWgUnsafe ¶
SetWgUnsafe - внешний мир может установить канал для уведомления о завершении
type TaskPool ¶
type TaskPool struct {
// contains filtered or unexported fields
}
TaskPool represent pooling of Task
type TaskState ¶
type TaskState int
TaskState - статусы жизненного цикла task
const ( TASK_STATE_NEW TaskState = iota // task создан TASK_STATE_POOL_GET // task получен из pool TASK_STATE_POOL_PUT // task отправлен в pool TASK_STATE_READY // task готов к обработкам TASK_STATE_IN_PROCESS // task выполняется TASK_STATE_DONE_SUCCESS // task завершился TASK_STATE_RECOVER_ERR // task остановился из-за паники TASK_STATE_TERMINATED_STOP_SIGNAL // task остановлен по причине получения сигнала об остановке TASK_STATE_TERMINATED_CTX_CLOSED // task остановлен по причине закрытия контекста TASK_STATE_TERMINATED_TIMEOUT // task остановлен по причине превышения timeout )
type Worker ¶
type Worker struct {
// contains filtered or unexported fields
}
Worker - выполняет task
func (*Worker) GetState ¶
func (wr *Worker) GetState() WorkerState
GetState - проверка состояния жизненного цикла worker
func (*Worker) Stop ¶
func (wr *Worker) Stop(shutdownMode PoolShutdownMode)
Stop - принудительная остановка worker, не дожидаясь отработки всей очереди
type WorkerError ¶
type WorkerError struct {
// contains filtered or unexported fields
}
WorkerError - ошибки и сбойный worker
type WorkerState ¶
type WorkerState int
WorkerState - статусы жизненного цикла worker
const ( WORKER_STATE_NEW WorkerState = iota // worker создан WORKER_STATE_WORKING // worker обрабатывает задачу WORKER_STATE_IDLE // worker простаивает WORKER_STATE_TERMINATING_PARENT_CTX_CLOSED // worker останавливается по причине закрытия родительского контекста WORKER_STATE_TERMINATING_STOP_SIGNAL // worker останавливается по причине получения сигнала об остановке WORKER_STATE_TERMINATING_TASK_CH_CLOSED // worker останавливается по причине закрытия канала задач WORKER_STATE_TERMINATED // worker остановлен WORKER_STATE_RECOVER_ERR // worker остановился из-за паники )