 README
¶
README
¶
Streaming
Streaming is a new protocol of the swarm bzz bundle of protocols. This protocol provides the basic logic for chunk-based data flow. It implements simple retrieve requests and delivery using priority queue. A data exchange stream is a directional flow of chunks between peers. The source of datachunks is the upstream, the receiver is called the downstream peer. Each streaming protocol defines an outgoing streamer and an incoming streamer, the former installing on the upstream, the latter on the downstream peer.
Subscribe on StreamerPeer launches an incoming streamer that sends a subscribe msg upstream. The streamer on the upstream peer handles the subscribe msg by installing the relevant outgoing streamer. The modules now engage in a process of upstream sending a sequence of hashes of chunks downstream (OfferedHashesMsg). The downstream peer evaluates which hashes are needed and get it delivered by sending back a msg (WantedHashesMsg).
Historical syncing is supported - currently not the right abstraction -- state kept across sessions by saving a series of intervals after their last batch actually arrived.
Live streaming is also supported, by starting session from the first item after the subscription.
Provable data exchange. In case a stream represents a swarm document's data layer or higher level chunks, streaming up to a certain index is always provable. It saves on sending intermediate chunks.
Using the streamer logic, various stream types are easy to implement:
- light node requests:
- url lookup with offset
- document download
- document upload
- syncing
- live session syncing
- historical syncing
- simple retrieve requests and deliveries
- swarm feeds streams
- receipting for finger pointing
Syncing
Syncing is the process that makes sure storer nodes end up storing all and only the chunks that are requested from them.
Requirements
- eventual consistency: so each chunk historical should be syncable
- since the same chunk can and will arrive from many peers, (network traffic should be optimised, only one transfer of data per chunk)
- explicit request deliveries should be prioritised higher than recent chunks received during the ongoing session which in turn should be higher than historical chunks.
- insured chunks should get receipted for finger pointing litigation, the receipts storage should be organised efficiently, upstream peer should also be able to find these receipts for a deleted chunk easily to refute their challenge.
- syncing should be resilient to cut connections, metadata should be persisted that keep track of syncing state across sessions, historical syncing state should survive restart
- extra data structures to support syncing should be kept at minimum
- syncing is not organized separately for chunk types (Swarm feed updates v regular content chunk)
- various types of streams should have common logic abstracted
Syncing is now entirely mediated by the localstore, ie., no processes or memory leaks due to network contention. When a new chunk is stored, its chunk hash is index by proximity bin
peers syncronise by getting the chunks closer to the downstream peer than to the upstream one. Consequently peers just sync all stored items for the kad bin the receiving peer falls into. The special case of nearest neighbour sets is handled by the downstream peer indicating they want to sync all kademlia bins with proximity equal to or higher than their depth.
This sync state represents the initial state of a sync connection session. Retrieval is dictated by downstream peers simply using a special streamer protocol.
Syncing chunks created during the session by the upstream peer is called live session syncing while syncing of earlier chunks is historical syncing.
Once the relevant chunk is retrieved, downstream peer looks up all hash segments in its localstore
and sends to the upstream peer a message with a a bitvector to indicate
missing chunks (e.g., for chunk k, hash with chunk internal index which case )
new items. In turn upstream peer sends the relevant chunk data alongside their index.
On sending chunks there is a priority queue system. If during looking up hashes in its localstore, downstream peer hits on an open request then a retrieve request is sent immediately to the upstream peer indicating that no extra round of checks is needed. If another peers syncer hits the same open request, it is slightly unsafe to not ask that peer too: if the first one disconnects before delivering or fails to deliver and therefore gets disconnected, we should still be able to continue with the other. The minimum redundant traffic coming from such simultaneous eventualities should be sufficiently rare not to warrant more complex treatment.
Session syncing involves downstream peer to request a new state on a bin from upstream. using the new state, the range (of chunks) between the previous state and the new one are retrieved and chunks are requested identical to the historical case. After receiving all the missing chunks from the new hashes, downstream peer will request a new range. If this happens before upstream peer updates a new state, we say that session syncing is live or the two peers are in sync. In general the time interval passed since downstream peer request up to the current session cursor is a good indication of a permanent (probably increasing) lag.
If there is no historical backlog, and downstream peer has an acceptable 'last synced' tag, then it is said to be fully synced with the upstream peer. If a peer is fully synced with all its storer peers, it can advertise itself as globally fully synced.
The downstream peer persists the record of the last synced offset. When the two peers disconnect and reconnect syncing can start from there. This situation however can also happen while historical syncing is not yet complete. Effectively this means that the peer needs to persist a record of an arbitrary array of offset ranges covered.
Delivery requests
once the appropriate ranges of the hashstream are retrieved and buffered, downstream peer just scans the hashes, looks them up in localstore, if not found, create a request entry. The range is referenced by the chunk index. Alongside the name (indicating the stream, e.g., content chunks for bin 6) and the range downstream peer sends a 128 long bitvector indicating which chunks are needed. Newly created requests are satisfied bound together in a waitgroup which when done, will promptt sending the next one. to be able to do check and storage concurrently, we keep a buffer of one, we start with two batches of hashes. If there is nothing to give, upstream peers SetNextBatch is blocking. Subscription ends with an unsubscribe. which removes the syncer from the map.
Canceling requests (for instance the late chunks of an erasure batch) should be a chan closed on the request
Simple request is also a subscribe different streaming protocols are different p2p protocols with same message types. the constructor is the Run function itself. which takes a streamerpeer as argument
provable streams
The swarm hash over the hash stream has many advantages. It implements a provable data transfer and provide efficient storage for receipts in the form of inclusion proofs usable for finger pointing litigation. When challenged on a missing chunk, upstream peer will provide an inclusion proof of a chunk hash against the state of the sync stream. In order to be able to generate such an inclusion proof, upstream peer needs to store the hash index (counting consecutive hash-size segments) alongside the chunk data and preserve it even when the chunk data is deleted until the chunk is no longer insured. if there is no valid insurance on the files the entry may be deleted. As long as the chunk is preserved, no takeover proof will be needed since the node can respond to any challenge. However, once the node needs to delete an insured chunk for capacity reasons, a receipt should be available to refute the challenge by finger pointing to a downstream peer. As part of the deletion protocol then, hashes of insured chunks to be removed are pushed to an infinite stream for every bin.
Downstream peer on the other hand needs to make sure that they can only be finger pointed about a chunk they did receive and store. For this the check of a state should be exhaustive. If historical syncing finishes on one state, all hashes before are covered, no surprises. In other words historical syncing this process is self verifying. With session syncing however, it is not enough to check going back covering the range from old offset to new. Continuity (i.e., that the new state is extension of the old) needs to be verified: after downstream peer reads the range into a buffer, it appends the buffer the last known state at the last known offset and verifies the resulting hash matches the latest state. Past intervals of historical syncing are checked via the session root. Upstream peer signs the states, downstream peers can use as handover proofs. Downstream peers sign off on a state together with an initial offset.
Once historical syncing is complete and the session does not lag, downstream peer only preserves the latest upstream state and store the signed version.
Upstream peer needs to keep the latest takeover states: each deleted chunk's hash should be covered by takeover proof of at least one peer. If historical syncing is complete, upstream peer typically will store only the latest takeover proof from downstream peer. Crucially, the structure is totally independent of the number of peers in the bin, so it scales extremely well.
implementation
The simplest protocol just involves upstream peer to prefix the key with the kademlia proximity order (say 0-15 or 0-31) and simply iterate on index per bin when syncing with a peer.
priority queues are used for sending chunks so that user triggered requests should be responded to first, session syncing second, and historical with lower priority. The request on chunks remains implemented as a dataless entry in the memory store. The lifecycle of this object should be more carefully thought through, ie., when it fails to retrieve it should be removed.
Address space gaps
In order to optimize Kademlia load balancing, performance and peer suggestion, we define the concept of address space gap
or simply gap.
A gap is a portion of the overlay address space in which the current node does not know any peer. It could be represented
as a range of addresses: 0xxx, meaning 0000-0111
The proximity order of a gap or gap po is the proximity order of that address space with respect to the nearest peer(s)
in the kademlia connected table (and considering also the current node address). For example if the node address is 0000,
the gap of addresses 1xxx has proximity order 0. However the proximity order of the gap 01xx has po 1.
The size of a gap is defined as the number of addresses that could fit in it. If the area of the whole address space is 1,
the size of a gap could be defined from the gap po as 1 / 2 ^ (po + 1). For example, our previous 1xxx gap has a size of
1 / (2 ^ 1) = 1/2. The size of 01xx is 1 / (2 ^ 2) = 1/4.
In order to increment performance of content retrieval and delivery the node should minimize the size of its gaps, because this
means that it knows peers near almost all addresses. If the minimum gap in the kademlia table is 4, it means that whatever
look up or forwarding done will be at least 4 po far away. On the other hand, if the node has a 0 po gap, it means that
for half the addresses, the next jump will be still 0 po away!.
Gaps for peer suggestion
The current kademlia bootstrap algorithm try to fill in the bins (or po spaces) until some level of saturation is reached.
In the process of doing that, the gaps will diminish, but not in the optimal way.
For example, if the node address is 00000000, it is connected only with one peer in bin 0 10000000 and the known
addresses for bin 0 are: 10000001 and 11000000. The current algorithm we will take the first callable one, so
for example, it may suggest 10000001 as next peer. This is not optimal, as the biggest gap in bin 0 will still be
po 1 => 11xxxxxx. If however, the algorithm is improved searching for a peer which covers a bigger gap, 11000000 would
be selected and now the biggest gaps will be po2 => 111xxxx and 101xxxx.
Additionally, even though the node does not have an address in a particular gap, it could still select the furthest away
from the current peers so it covers a bigger gap. In the previous example with node 00000000 and one peer already connected
10000000, if the known addresses are 10000001 and 1001000, the best suggestion would be the last one, because it is po 3
from the nearest peer as opposed to 10000001 that is only po 7 away. The best case will cover a gap of po 3 size
(1/16 of area or 16 addresses) and the other one just po 7 size (1/256 area or 1 address).
Gaps and load balancing
One additional benefit in considering gaps is load balancing. If the target addresses are distributed randomly
(although address popularity is another problem that can also be studied from the gap perspective), the request will
be automatically load balanced if we try to connect to peers covering the bigger gaps. Continuing with our example,
if in bin 0 we have peers 10000000 and 10000001 (Fig. 1), almost all addresses in space 1xxxxxxx, that is, half of the
addresses will have the same distance from both peers. If we need to send to some of those address we will need to use
one of those peers. This could be done randomly, always the first or with some load balancing accounting to use the least
used one.
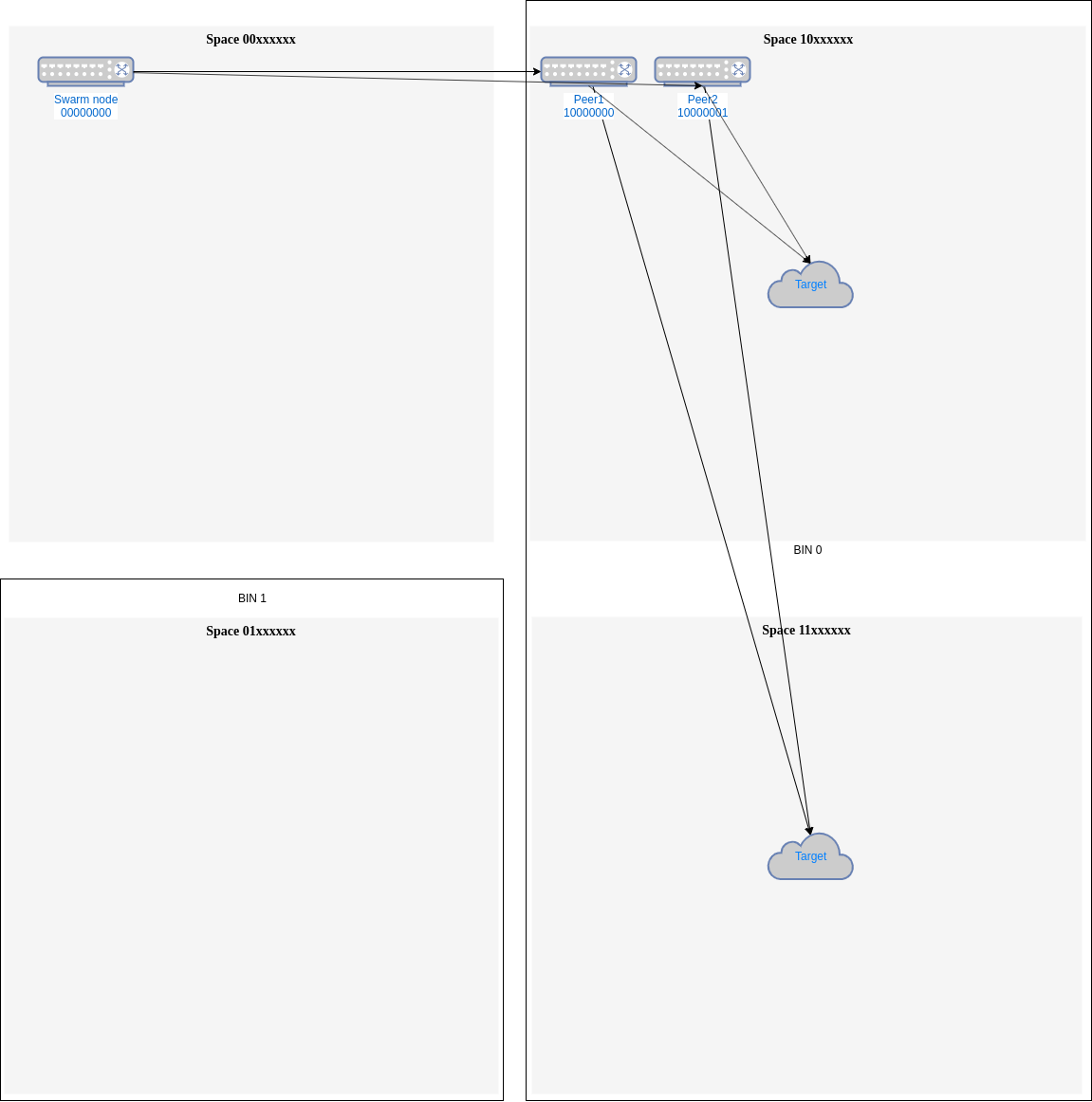 Fig.1 - Closer peers needs an external Load Balancing mechanism
Fig.1 - Closer peers needs an external Load Balancing mechanism
This last method will still be useful, but if the gap filling strategy is used, most probably both peers will
be separated enough that they never compete for an address and a natural load balancing will be made among them (for example,
10000000 and 11000000 will be used each for half the addresses in bin 0 (Fig. 2)).
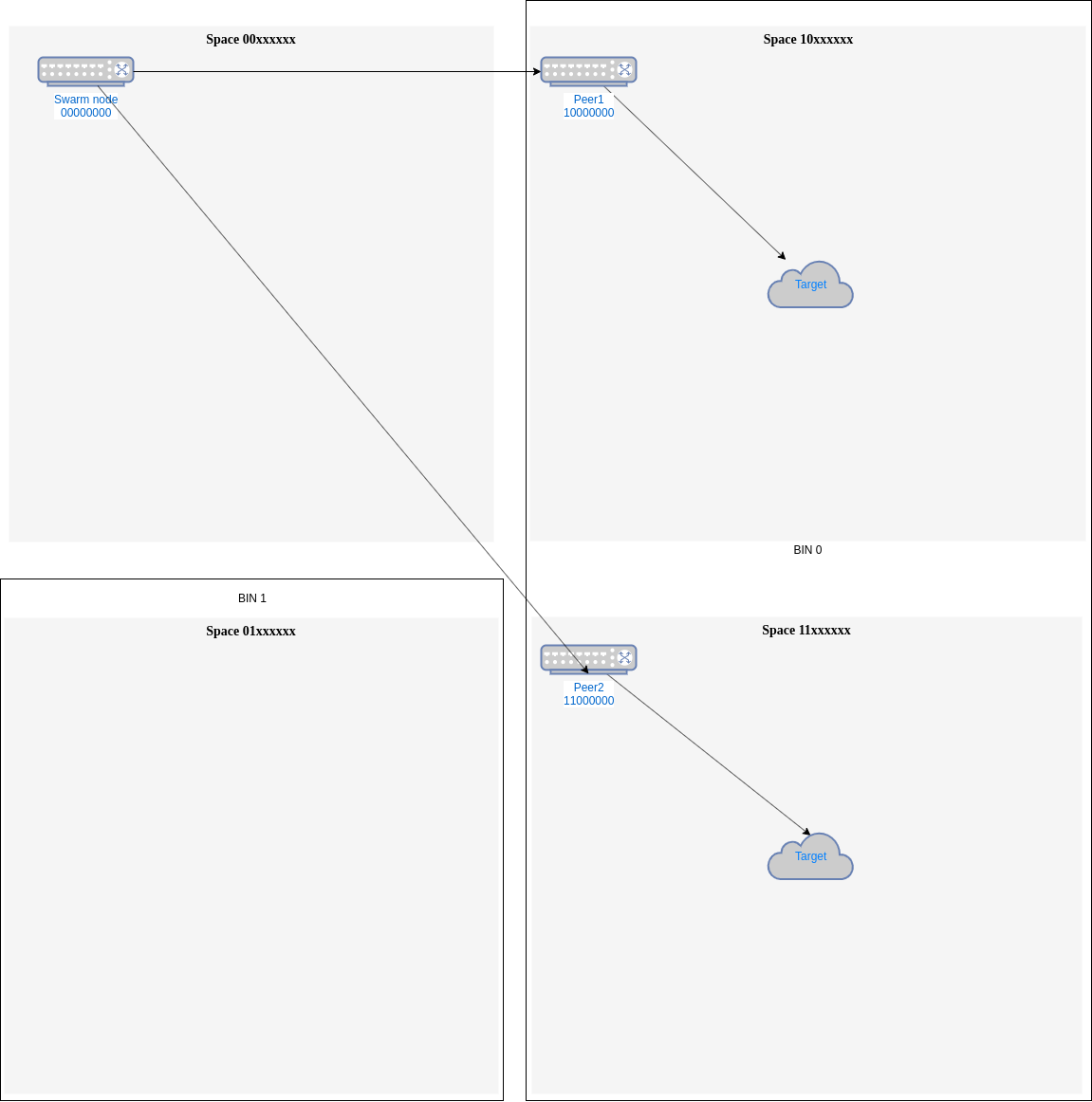 Fig.2 - Peers chosen by space address gap have a natural load balancing
Fig.2 - Peers chosen by space address gap have a natural load balancing
Implementation
The search for gaps can be done easily using a proximity order tree or pot. Traversing the bins of a node, a gap is
found if there is some of the po's missing starting from furthest (left). In each level the starting po to search for is the
parent po (not 0, because in the second level, under a node of po=0, the minimum po that could be found is 1).
Implementation of the function that looks for the bigger Gap in a pot can be seen in
pot.BiggestAddressGap. That function returns the biggest gap in the form of a po and
a node under the gap can be found.
This function is used in kademlia.suggestPeerInBinByGap, which it returns a BzzAddress in a particular bin which fills
up the biggest address gap. This function is not used in SuggestPeer, but it will be enough to replace the call to
suggestPeerInBin with the new one.
Further improvements
Instead of the size of a gap, maybe it could be more interesting to see the ratio between size and number of current
peers serving that gap. If we have n current peers that are equidistant to a particular gap of size s,
the load of each of these peers will be on average s/n.
We can define a gap's temperature as that number s/n. When looking for new peers to connect, instead of looking for
bigger gaps we could look for hotter gaps.
For example, if in our first example, we can't find a peer in 11xxxxxx and we instead, used the best peer, we could end
with the configuration in Fig. 3.
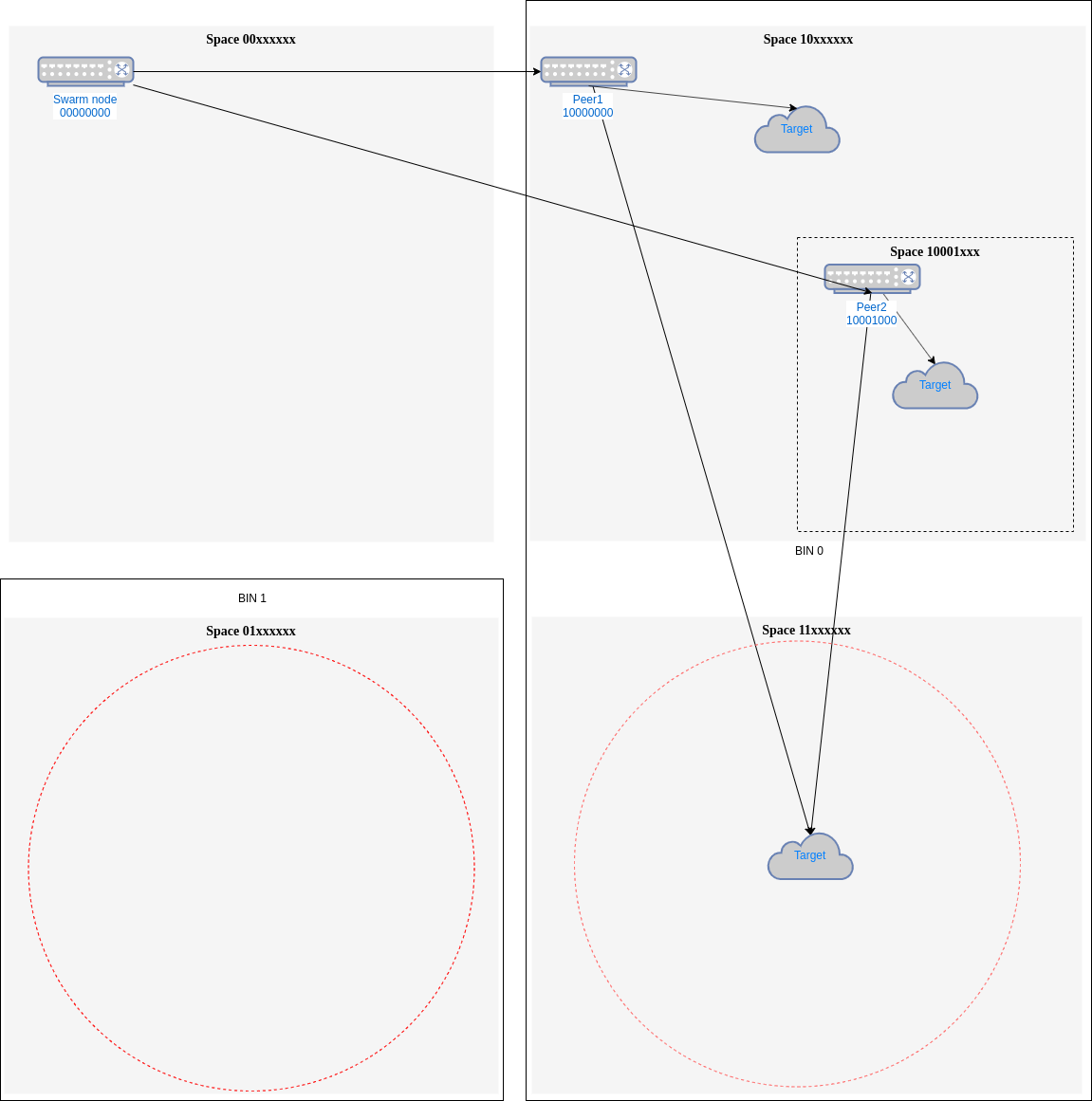 Fig. 3 - Comparing gaps temperature
Fig. 3 - Comparing gaps temperature
Here we still have 11xxxxxx as the biggest gap (po=1, size 1/4), same size as 01xxxxxx. But if consider temperature,
01xxxxxx is hotter because is served only by our node 00000000, being its temperature is (1/4)/ 1 = 1/4. However,
11xxxxxx is now served by two peers, so its temperature is (1/4) / 2 = 1/8, and that will mean that we will select
01xxxxxx as the hotter one.
There is a way of implementing temperature calculation so its cost it is the same as looking for biggest gap. Temperature
can be calculated on the fly as the gap is found using a pot.
Other metrics could be considered in the temperature, as recently number of requests per address space, performance of current peers...
 Documentation
¶
Documentation
¶
Overview ¶
Copyright 2019 The Swarm Authors This file is part of the Swarm library.
The Swarm library is free software: you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
The Swarm library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with the Swarm library. If not, see <http://www.gnu.org/licenses/>.
Index ¶
- Constants
- Variables
- func Label(e *entry) string
- func LogAddrs(nns [][]byte) string
- func NewCapabilityIndex(c capability.Capability) *capabilityIndex
- func NewDefaultIndex() *capabilityIndex
- func NewEnode(params *EnodeParams) (*enode.Node, error)
- func NewEnodeRecord(params *EnodeParams) (*enr.Record, error)
- func NewPeerPotMap(neighbourhoodSize int, addrs [][]byte) map[string]*PeerPot
- func PrivateKeyToBzzKey(prvKey *ecdsa.PrivateKey) []byte
- type Bzz
- func (b *Bzz) APIs() []rpc.API
- func (b *Bzz) GetOrCreateHandshake(peerID enode.ID) (*HandshakeMsg, bool)
- func (b *Bzz) NodeInfo() interface{}
- func (b *Bzz) Protocols() []p2p.Protocol
- func (b *Bzz) RunProtocol(spec *protocols.Spec, run func(*BzzPeer) error) func(*p2p.Peer, p2p.MsgReadWriter) error
- func (b *Bzz) Stop() error
- func (b *Bzz) UpdateLocalAddr(byteaddr []byte) *BzzAddr
- type BzzAddr
- func (a *BzzAddr) Address() []byte
- func (b *BzzAddr) DecodeRLP(s *rlp.Stream) error
- func (b *BzzAddr) EncodeRLP(w io.Writer) error
- func (a *BzzAddr) ID() enode.ID
- func (a *BzzAddr) Over() []byte
- func (a *BzzAddr) ShortOver() string
- func (a *BzzAddr) ShortString() string
- func (a *BzzAddr) ShortUnder() string
- func (a *BzzAddr) String() string
- func (a *BzzAddr) Under() []byte
- func (a *BzzAddr) Update(na *BzzAddr) *BzzAddr
- func (b *BzzAddr) WithCapabilities(c *capability.Capabilities) *BzzAddr
- type BzzConfig
- type BzzPeer
- type ENRAddrEntry
- type ENRBootNodeEntry
- type EnodeParams
- type HandshakeMsg
- type Health
- type Hive
- func (h *Hive) NodeInfo() interface{}
- func (h *Hive) NotifyDepth(depth uint8)
- func (h *Hive) NotifyPeer(p *BzzAddr)
- func (h *Hive) Peer(id enode.ID) *BzzPeer
- func (h *Hive) PeerInfo(id enode.ID) interface{}
- func (h *Hive) Run(p *BzzPeer) error
- func (h *Hive) Start(server *p2p.Server) error
- func (h *Hive) Stop() error
- type HiveParams
- type KadParams
- type Kademlia
- func (k *Kademlia) BaseAddr() []byte
- func (k *Kademlia) EachAddr(base []byte, o int, f func(*BzzAddr, int) bool)
- func (k *Kademlia) EachAddrFiltered(base []byte, capKey string, o int, f func(*BzzAddr, int) bool) error
- func (k *Kademlia) EachBinDesc(base []byte, minProximityOrder int, consumer PeerBinConsumer)
- func (k *Kademlia) EachBinDescFiltered(base []byte, capKey string, minProximityOrder int, consumer PeerBinConsumer) error
- func (k *Kademlia) EachConn(base []byte, o int, f func(*Peer, int) bool)
- func (k *Kademlia) EachConnFiltered(base []byte, capKey string, o int, f func(*Peer, int) bool) error
- func (k *Kademlia) GetHealthInfo(pp *PeerPot) *Health
- func (k *Kademlia) IsClosestTo(addr []byte, filter func(*BzzPeer) bool) (closest bool)
- func (k *Kademlia) IsWithinDepth(addr []byte) bool
- func (k *Kademlia) KademliaInfo() KademliaInfo
- func (k *Kademlia) NeighbourhoodDepth() int
- func (k *Kademlia) NeighbourhoodDepthCapability(s string) (int, error)
- func (k *Kademlia) Off(p *Peer)
- func (k *Kademlia) On(p *Peer) (uint8, bool)
- func (k *Kademlia) Register(peers ...*BzzAddr) error
- func (k *Kademlia) RegisterCapabilityIndex(s string, c capability.Capability) error
- func (k *Kademlia) Saturation() int
- func (k *Kademlia) String() string
- func (k *Kademlia) SubscribeToNeighbourhoodDepthChange() (c <-chan struct{}, unsubscribe func())
- func (k *Kademlia) SubscribeToPeerChanges() *pubsubchannel.Subscription
- func (k *Kademlia) SuggestPeer() (suggestedPeer *BzzAddr, saturationDepth int, changed bool)
- type KademliaBackend
- type KademliaInfo
- type KademliaLoadBalancer
- func (klb *KademliaLoadBalancer) EachBinDesc(base []byte, consumeBin LBBinConsumer)
- func (klb *KademliaLoadBalancer) EachBinFiltered(base []byte, capKey string, consumeBin LBBinConsumer) error
- func (klb *KademliaLoadBalancer) EachBinNodeAddress(consumeBin LBBinConsumer)
- func (klb *KademliaLoadBalancer) Stop()
- type LBBin
- type LBBinConsumer
- type LBPeer
- type Peer
- type PeerBin
- type PeerBinConsumer
- type PeerConsumer
- type PeerIterator
- type PeerPot
Constants ¶
const (
DefaultNetworkID = 4
)
Variables ¶
var BzzSpec = &protocols.Spec{ Name: "bzz", Version: 14, MaxMsgSize: 10 * 1024 * 1024, Messages: []interface{}{ HandshakeMsg{}, }, }
BzzSpec is the spec of the generic swarm handshake
var (
CapabilityID = capability.CapabilityID(0)
)
var DefaultTestNetworkID = rand.Uint64()
var DiscoverySpec = &protocols.Spec{
Name: "hive",
Version: 11,
MaxMsgSize: 10 * 1024 * 1024,
Messages: []interface{}{
peersMsg{},
subPeersMsg{},
},
}
DiscoverySpec is the spec for the bzz discovery subprotocols
var Pof = pot.DefaultPof(256)
Functions ¶
func NewCapabilityIndex ¶ added in v0.5.0
func NewCapabilityIndex(c capability.Capability) *capabilityIndex
NewCapabilityIndex creates a new capability index with a copy the provided capabilities array
func NewDefaultIndex ¶ added in v0.5.3
func NewDefaultIndex() *capabilityIndex
NewDefaultIndex creates a new index for no capability
func NewEnode ¶
func NewEnode(params *EnodeParams) (*enode.Node, error)
NewEnode creates a new enode object for the given parameters
func NewEnodeRecord ¶
func NewEnodeRecord(params *EnodeParams) (*enr.Record, error)
NewEnodeRecord creates a new valid swarm node ENR record from the given parameters
func NewPeerPotMap ¶
NewPeerPotMap creates a map of pot record of *BzzAddr with keys as hexadecimal representations of the address. the NeighbourhoodSize of the passed kademlia is used used for testing only TODO move to separate testing tools file
func PrivateKeyToBzzKey ¶
func PrivateKeyToBzzKey(prvKey *ecdsa.PrivateKey) []byte
PrivateKeyToBzzKey create a swarm overlay address from the given private key
Types ¶
type Bzz ¶
Bzz is the swarm protocol bundle
func NewBzz ¶
func NewBzz(config *BzzConfig, kad *Kademlia, store state.Store, streamerSpec, retrievalSpec *protocols.Spec, streamerRun, retrievalRun func(*BzzPeer) error) *Bzz
NewBzz is the swarm protocol constructor arguments * bzz config * overlay driver * peer store
func (*Bzz) APIs ¶
APIs returns the APIs offered by bzz * hive Bzz implements the node.Service interface
func (*Bzz) GetOrCreateHandshake ¶
func (b *Bzz) GetOrCreateHandshake(peerID enode.ID) (*HandshakeMsg, bool)
GetHandshake returns the bzz handhake that the remote peer with peerID sent
func (*Bzz) NodeInfo ¶
func (b *Bzz) NodeInfo() interface{}
NodeInfo returns the node's overlay address
func (*Bzz) Protocols ¶
Protocols return the protocols swarm offers Bzz implements the node.Service interface * handshake/hive * discovery
func (*Bzz) RunProtocol ¶
func (b *Bzz) RunProtocol(spec *protocols.Spec, run func(*BzzPeer) error) func(*p2p.Peer, p2p.MsgReadWriter) error
RunProtocol is a wrapper for swarm subprotocols returns a p2p protocol run function that can be assigned to p2p.Protocol#Run field arguments:
- p2p protocol spec
- run function taking BzzPeer as argument this run function is meant to block for the duration of the protocol session on return the session is terminated and the peer is disconnected
the protocol waits for the bzz handshake is negotiated the overlay address on the BzzPeer is set from the remote handshake
func (*Bzz) UpdateLocalAddr ¶
UpdateLocalAddr updates underlayaddress of the running node
type BzzAddr ¶
type BzzAddr struct {
OAddr []byte
UAddr []byte
Capabilities *capability.Capabilities
}
BzzAddr implements the PeerAddr interface
func NewBzzAddr ¶ added in v0.5.0
NewBzzAddr creates a new BzzAddr with the specified byte values for over- and underlayaddresses It will contain an empty capabilities object
func NewBzzAddrFromEnode ¶ added in v0.5.0
NewBzzAddrFromEnode creates a BzzAddr where the overlay address is the byte representation of the enode i It is only used for test purposes TODO: This method should be replaced by (optionally deterministic) generation of addresses using NewEnode and PrivateKeyToBzzKey
func RandomBzzAddr ¶ added in v0.5.0
func RandomBzzAddr() *BzzAddr
RandomBzzAddr is a utility method generating a private key and corresponding enode id It in turn calls NewBzzAddrFromEnode to generate a corresponding overlay address from enode
func (*BzzAddr) ShortOver ¶ added in v0.5.5
ShortOver returns shortened version of Overlay address It can be used for logging
func (*BzzAddr) ShortString ¶ added in v0.5.5
ShortString returns shortened versions of overlay and underlay address in a format: shortOver:shortUnder It can be used for logging
func (*BzzAddr) ShortUnder ¶ added in v0.5.5
ShortUnder returns shortened version of Underlay address It can be used for logging
func (*BzzAddr) WithCapabilities ¶ added in v0.5.0
func (b *BzzAddr) WithCapabilities(c *capability.Capabilities) *BzzAddr
WithCapabilities is a chained constructor method to set the capabilities array for a BzzAddr
type BzzConfig ¶
type BzzConfig struct {
Address *BzzAddr
HiveParams *HiveParams
NetworkID uint64
LightNode bool // temporarily kept as we still only define light/full on operational level
BootnodeMode bool
SyncEnabled bool
}
BzzConfig captures the config params used by the hive
type BzzPeer ¶
type BzzPeer struct {
*protocols.Peer // represents the connection for online peers
*BzzAddr // remote address -> implements Addr interface = protocols.Peer
// contains filtered or unexported fields
}
BzzPeer is the bzz protocol view of a protocols.Peer (itself an extension of p2p.Peer) implements the Peer interface and all interfaces Peer implements: Addr, OverlayPeer
func NewBzzPeer ¶
type ENRAddrEntry ¶
type ENRAddrEntry struct {
// contains filtered or unexported fields
}
ENRAddrEntry is the entry type to store the bzz key in the enode
func NewENRAddrEntry ¶
func NewENRAddrEntry(addr []byte) *ENRAddrEntry
func (ENRAddrEntry) Address ¶
func (b ENRAddrEntry) Address() []byte
type ENRBootNodeEntry ¶
type ENRBootNodeEntry bool
func (ENRBootNodeEntry) ENRKey ¶
func (b ENRBootNodeEntry) ENRKey() string
type EnodeParams ¶
type EnodeParams struct {
PrivateKey *ecdsa.PrivateKey
EnodeKey *ecdsa.PrivateKey
Lightnode bool
Bootnode bool
}
EnodeParams contains the parameters used to create new Enode Records
type HandshakeMsg ¶
type HandshakeMsg struct {
Version uint64
NetworkID uint64
Addr *BzzAddr
// contains filtered or unexported fields
}
Handshake
* Version: 8 byte integer version of the protocol * NetworkID: 8 byte integer network identifier * Addr: the address advertised by the node including underlay and overlay connecctions * Capabilities: the capabilities bitvector
func (*HandshakeMsg) String ¶
func (bh *HandshakeMsg) String() string
String pretty prints the handshake
type Health ¶
type Health struct {
KnowNN bool // whether node knows all its neighbours
CountKnowNN int // amount of neighbors known
MissingKnowNN [][]byte // which neighbours we should have known but we don't
ConnectNN bool // whether node is connected to all its neighbours
CountConnectNN int // amount of neighbours connected to
MissingConnectNN [][]byte // which neighbours we should have been connected to but we're not
// Saturated: if in all bins < depth number of connections >= MinBinsize or,
// if number of connections < MinBinSize, to the number of available peers in that bin
Saturated bool
Hive string
}
Health state of the Kademlia used for testing only
type Hive ¶
type Hive struct {
*HiveParams // settings
*Kademlia // the overlay connectiviy driver
Store state.Store // storage interface to save peers across sessions
// contains filtered or unexported fields
}
Hive manages network connections of the swarm node
func NewHive ¶
func NewHive(params *HiveParams, kad *Kademlia, store state.Store) *Hive
NewHive constructs a new hive HiveParams: config parameters Kademlia: connectivity driver using a network topology StateStore: to save peers across sessions
func (*Hive) NodeInfo ¶
func (h *Hive) NodeInfo() interface{}
NodeInfo function is used by the p2p.server RPC interface to display protocol specific node information
func (*Hive) NotifyDepth ¶ added in v0.5.3
NotifyDepth sends a message to all connections if depth of saturation is changed
func (*Hive) NotifyPeer ¶ added in v0.5.3
NotifyPeer informs all peers about a newly added node
func (*Hive) Peer ¶
Peer returns a bzz peer from the Hive. If there is no peer with the provided enode id, a nil value is returned.
func (*Hive) PeerInfo ¶
PeerInfo function is used by the p2p.server RPC interface to display protocol specific information any connected peer referred to by their NodeID
type HiveParams ¶
type HiveParams struct {
Discovery bool // if want discovery of not
DisableAutoConnect bool // this flag disables the auto connect loop
PeersBroadcastSetSize uint8 // how many peers to use when relaying
MaxPeersPerRequest uint8 // max size for peer address batches
KeepAliveInterval time.Duration
}
HiveParams holds the config options to hive
func NewHiveParams ¶
func NewHiveParams() *HiveParams
NewHiveParams returns hive config with only the
type KadParams ¶
type KadParams struct {
// adjustable parameters
MaxProxDisplay int // number of rows the table shows
NeighbourhoodSize int // nearest neighbour core minimum cardinality
MinBinSize int // minimum number of peers in a row
MaxBinSize int // maximum number of peers in a row before pruning
RetryInterval int64 // initial interval before a peer is first redialed
RetryExponent int // exponent to multiply retry intervals with
MaxRetries int // maximum number of redial attempts
// function to sanction or prevent suggesting a peer
Reachable func(*BzzAddr) bool `json:"-"`
Capabilities *capability.Capabilities `json:"-"`
}
KadParams holds the config params for Kademlia
func NewKadParams ¶
func NewKadParams() *KadParams
NewKadParams returns a params struct with default values
type Kademlia ¶
type Kademlia struct {
*KadParams // Kademlia configuration parameters
// contains filtered or unexported fields
}
Kademlia is a table of live peers and a db of known peers (node records)
func NewKademlia ¶
NewKademlia creates a Kademlia table for base address addr with parameters as in params if params is nil, it uses default values
func (*Kademlia) EachAddr ¶
EachAddr called with (base, po, f) is an iterator applying f to each known peer that has proximity order o or less as measured from the base if base is nil, kademlia base address is used
func (*Kademlia) EachAddrFiltered ¶ added in v0.5.0
func (k *Kademlia) EachAddrFiltered(base []byte, capKey string, o int, f func(*BzzAddr, int) bool) error
EachAddrFiltered performs the same action as EachAddr with the difference that it will only return peers that matches the specified capability index filter
func (*Kademlia) EachBinDesc ¶ added in v0.5.3
func (k *Kademlia) EachBinDesc(base []byte, minProximityOrder int, consumer PeerBinConsumer)
Traverse bins (PeerBin) in descending order of proximity (so closest first) with respect to a given address base. It will stop iterating whenever the supplied consumer returns false, the bins run out or a bin is found with proximity order less than minProximityOrder param.
func (*Kademlia) EachBinDescFiltered ¶ added in v0.5.3
func (k *Kademlia) EachBinDescFiltered(base []byte, capKey string, minProximityOrder int, consumer PeerBinConsumer) error
Traverse bins in descending order filtered by capabilities. Sane as EachBinDesc but taking into account only peers with those capabilities.
func (*Kademlia) EachConn ¶
EachConn is an iterator with args (base, po, f) applies f to each live peer that has proximity order po or less as measured from the base if base is nil, kademlia base address is used
func (*Kademlia) EachConnFiltered ¶ added in v0.5.0
func (k *Kademlia) EachConnFiltered(base []byte, capKey string, o int, f func(*Peer, int) bool) error
EachConnFiltered performs the same action as EachConn with the difference that it will only return peers that matches the specified capability index filter
func (*Kademlia) GetHealthInfo ¶
GetHealthInfo reports the health state of the kademlia connectivity
The PeerPot argument provides an all-knowing view of the network The resulting Health object is a result of comparisons between what is the actual composition of the kademlia in question (the receiver), and what SHOULD it have been when we take all we know about the network into consideration.
used for testing only
func (*Kademlia) IsClosestTo ¶ added in v0.5.0
IsClosestTo returns true if self is the closest peer to addr among filtered peers ie. return false iff there is a peer that - filter(bzzpeer) == true AND - pot.DistanceCmp(addr, peeraddress, selfaddress) == 1
func (*Kademlia) IsWithinDepth ¶ added in v0.5.3
IsWithinDepth checks whether a given address falls within this node's saturation depth
func (*Kademlia) KademliaInfo ¶ added in v0.4.3
func (k *Kademlia) KademliaInfo() KademliaInfo
func (*Kademlia) NeighbourhoodDepth ¶
NeighbourhoodDepth returns the value calculated by depthForPot function in setNeighbourhoodDepth method.
func (*Kademlia) NeighbourhoodDepthCapability ¶ added in v0.5.0
func (*Kademlia) Register ¶
Register enters each address as kademlia peer record into the database of known peer addresses
func (*Kademlia) RegisterCapabilityIndex ¶ added in v0.5.0
func (k *Kademlia) RegisterCapabilityIndex(s string, c capability.Capability) error
RegisterCapabilityIndex adds an entry to the capability index of the kademlia The capability index is associated with the supplied string s Any peers matching any bits set in the capability in the index, will be added to the index (or removed on removal)
func (*Kademlia) Saturation ¶
Saturation returns the smallest po value in which the node has less than MinBinSize peers if the iterator reaches neighbourhood radius, then the last bin + 1 is returned
func (*Kademlia) SubscribeToNeighbourhoodDepthChange ¶
func (k *Kademlia) SubscribeToNeighbourhoodDepthChange() (c <-chan struct{}, unsubscribe func())
SubscribeToNeighbourhoodDepthChange returns the channel that signals when neighbourhood depth value is changed. The current neighbourhood depth is returned by NeighbourhoodDepth method. Returned function unsubscribes the channel from signaling and releases the resources. Returned function is safe to be called multiple times.
func (*Kademlia) SubscribeToPeerChanges ¶ added in v0.5.3
func (k *Kademlia) SubscribeToPeerChanges() *pubsubchannel.Subscription
SubscribeToPeerChanges returns the channel that signals when a new Peer is added or removed from the table. Returned function unsubscribes the channel from signaling and releases the resources. Returned function is safe to be called multiple times.
type KademliaBackend ¶ added in v0.5.3
type KademliaBackend interface {
SubscribeToPeerChanges() *pubsubchannel.Subscription
BaseAddr() []byte
EachBinDesc(base []byte, minProximityOrder int, consumer PeerBinConsumer)
EachBinDescFiltered(base []byte, capKey string, minProximityOrder int, consumer PeerBinConsumer) error
EachConn(base []byte, o int, f func(*Peer, int) bool)
}
KademliaBackend is the required interface of KademliaLoadBalancer.
type KademliaInfo ¶ added in v0.4.3
type KademliaLoadBalancer ¶ added in v0.5.3
type KademliaLoadBalancer struct {
// contains filtered or unexported fields
}
KademliaLoadBalancer tries to balance request to the peers in Kademlia returning the peers sorted by least recent used whenever several will be returned with the same po to a particular address. The user of KademliaLoadBalancer should signal if the returned element (LBPeer) has been used with the function lbPeer.AddUseCount()
func NewKademliaLoadBalancer ¶ added in v0.5.3
func NewKademliaLoadBalancer(kademlia KademliaBackend, useNearestNeighbourInit bool) *KademliaLoadBalancer
Creates a new KademliaLoadBalancer from a KademliaBackend. If useNearestNeighbourInit is true the nearest neighbour peer use count will be used when a peer is initialized. If not, least used peer use count in same bin as new peer will be used. It is not clear which one is better, when this load balancer would be used in several use cases we could do take some decision.
func (*KademliaLoadBalancer) EachBinDesc ¶ added in v0.5.3
func (klb *KademliaLoadBalancer) EachBinDesc(base []byte, consumeBin LBBinConsumer)
EachBinDesc returns all bins in descending order from the perspective of base address. All peers in that bin will be provided to the LBBinConsumer sorted by least used first.
func (*KademliaLoadBalancer) EachBinFiltered ¶ added in v0.5.3
func (klb *KademliaLoadBalancer) EachBinFiltered(base []byte, capKey string, consumeBin LBBinConsumer) error
EachBinFiltered returns all bins in descending order from the perspective of base address. Only peers with the provided capabilities capKey are considered. All peers in that bin will be provided to the LBBinConsumer sorted by least used first.
func (*KademliaLoadBalancer) EachBinNodeAddress ¶ added in v0.5.3
func (klb *KademliaLoadBalancer) EachBinNodeAddress(consumeBin LBBinConsumer)
EachBinNodeAddress calls EachBinDesc with the base address of kademlia (the node address)
func (*KademliaLoadBalancer) Stop ¶ added in v0.5.3
func (klb *KademliaLoadBalancer) Stop()
Stop unsubscribe from notifiers
type LBBinConsumer ¶ added in v0.5.3
LBBinConsumer will be provided with a list of LBPeer's in LB criteria ordering (currently in least used ordering). Should return true if it must continue iterating LBBin's or stops if false.
type LBPeer ¶ added in v0.5.3
type LBPeer struct {
Peer *Peer
// contains filtered or unexported fields
}
An LBPeer represents a peer with a AddUseCount() function to signal that the peer has been used in order to account it for LB sorting criteria.
func (*LBPeer) AddUseCount ¶ added in v0.5.3
func (lbPeer *LBPeer) AddUseCount()
AddUseCount is called to account a use for these peer. Should be called if the peer is actually used.
type Peer ¶
type Peer struct {
*BzzPeer
// contains filtered or unexported fields
}
Peer wraps BzzPeer and embeds Kademlia overlay connectivity driver
func (*Peer) Key ¶ added in v0.5.3
Key returns a string representation of this peer to be used in maps.
func (*Peer) Label ¶ added in v0.5.3
Label returns a short string representation for debugging purposes
func (*Peer) NotifyDepth ¶
NotifyDepth sends a subPeers Msg to the receiver notifying them about a change in the depth of saturation
func (*Peer) NotifyPeer ¶
NotifyPeer notifies the remote node (recipient) about a peer if the peer's PO is within the recipients advertised depth OR the peer is closer to the recipient than self unless already notified during the connection session
type PeerBin ¶ added in v0.5.3
type PeerBin struct {
ProximityOrder int
Size int
PeerIterator PeerIterator
}
PeerBin represents a bin in the Kademlia table. Contains a PeerIterator to traverse the peer entries inside it.
type PeerBinConsumer ¶ added in v0.5.3
PeerBinConsumer consumes a peerBin. It should return true if it wishes to continue iterating bins.
type PeerConsumer ¶ added in v0.5.3
type PeerConsumer func(entry *entry) bool
PeerConsumer consumes a peer entry in a PeerIterator. The function should return true if it wishes to continue iterating.
type PeerIterator ¶ added in v0.5.3
type PeerIterator func(PeerConsumer) bool
PeerIterator receives a PeerConsumer and iterates over peer entry until some of the executions of PeerConsumer returns false or the entries run out. It returns the last value returned by the last PeerConsumer execution.
 Source Files
¶
Source Files
¶
 Directories
¶
Directories
¶
| Path | Synopsis |
|---|---|
|
You can run this simulation using go run ./swarm/network/simulations/overlay.go
|
You can run this simulation using go run ./swarm/network/simulations/overlay.go |